4D-Former: Multimodal 4D Panoptic Segmentation

Abstract
4D panoptic segmentation is a challenging but practically useful task that requires every point in a LiDAR point-cloud sequence to be assigned a semantic class label, and individual objects to be segmented and tracked over time. Existing approaches utilize only LiDAR inputs which convey limited information in regions with point sparsity. This problem can, however, be mitigated by utilizing RGB camera images which offer appearance-based information that can reinforce the geometry-based LiDAR features. Motivated by this, we propose 4D-Former: a novel method for 4D panoptic segmentation which leverages both LiDAR and image modalities, and predicts semantic masks as well as temporally consistent object masks for the input point-cloud sequence. We encode semantic classes and objects using a set of concise queries which absorb feature information from both data modalities. Additionally, we propose a learned mechanism to associate object tracks over time which reasons over both appearance and spatial location. We apply 4D-Former to the nuScenes and SemanticKITTI datasets where it achieves state-of-the-art results.
Overview
We propose 4D-Former, a novel approach for 4D panoptic segmentation that effectively fuses information from LiDAR and camera data to output high quality semantic segmentation labels as well as temporally consistent object masks for the input point cloud sequence. To the best of our knowledge, this is the first work that explores multi-sensor fusion for 4D panoptic point cloud segmentation.

Video
Motivation
Existing 4D panoptic segmentation methods utilize only LiDAR data which provides accurate 3D geometry, but is sparse at range and lacks visual appearance information that might be important to disambiguate certain classes. Below is an example of LiDAR scans being sparse which pose significant challenges for reasoning in those regions. Note how the three points referred by the arrow lag context and are difficult to interpret.

In contrast, cameras offer rich context and the appearance cues which are very useful for perceiving areas where LiDAR scans are very sparse. In this example, we see that the three LiDAR points project onto the traffic signs which make it easy to assign a semantic label to them.

Method
We present 4D-Former, a novel transformer-based architecture that effectively combines sparse geometric features from LiDAR with dense contextual features from cameras. In particular, it models object instances and semantic classes using concise, learnable queries, followed by iterative refinement by self-attention and cross-attention to LiDAR and camera image features.
4D-Former operates in a sliding window fashion, as demonstrated in the illustration below. At each iteration, 4D-Former takes as input the current LiDAR scan at time t, the past scan at t – 1, and the camera images at time t. Our input encoder extracts image features from the camera images, and point-level and voxel-level features by fusing information from the LiDAR point clouds and camera features. These features are then utilized in our transformer-based panoptic decoder, in which the queries distill information about the objects and semantic classes present in the scene. The decoder header then generates semantic and tracklet predictions for these two LiDAR scans. To make the tracklet predictions consistent over the entire input sequence, we propose a novel Tracklet Association Module which maintains a history of previously observed object tracks, and associates them based on a learning-based matching objective.

Comparison against state-of-the-art
4D-Former significantly outperforms all previous methods on the nuScenes 4D panoptic segmentation benchmark, demonstrating its ability to effectively reason over multimodal inputs.
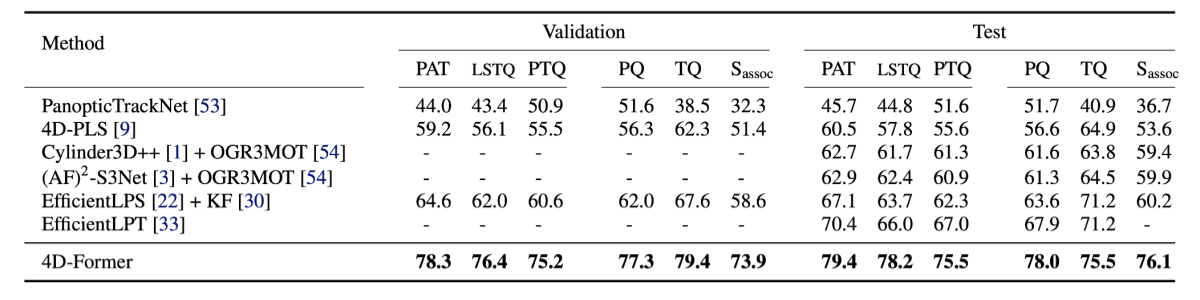
Ablation
To understand the effect of each fusion component, we conduct ablation studies on the nuScenes dataset. For these experiments, we subsample the training set by using only every fourth frame to save time and resources. The final model is also re-trained with this setting for a fair comparison. The following four models were evaluated across various metrics, including Panoptic Tracking (PAT), LiDAR Segmentaion and Tracking Quality (LSTQ), Panoptic Tracking Quality (PTQ), and Panoptic Quality (PQ):
- A LiDAR-only model that does not incorporate any image feature fusion.
- A model that employs point-level fusion in the encoder.
- A model that utilizes cross-attention fusion in the panoptic decoder.
- 4D-Former, which incorporates both types of multimodal fusion.
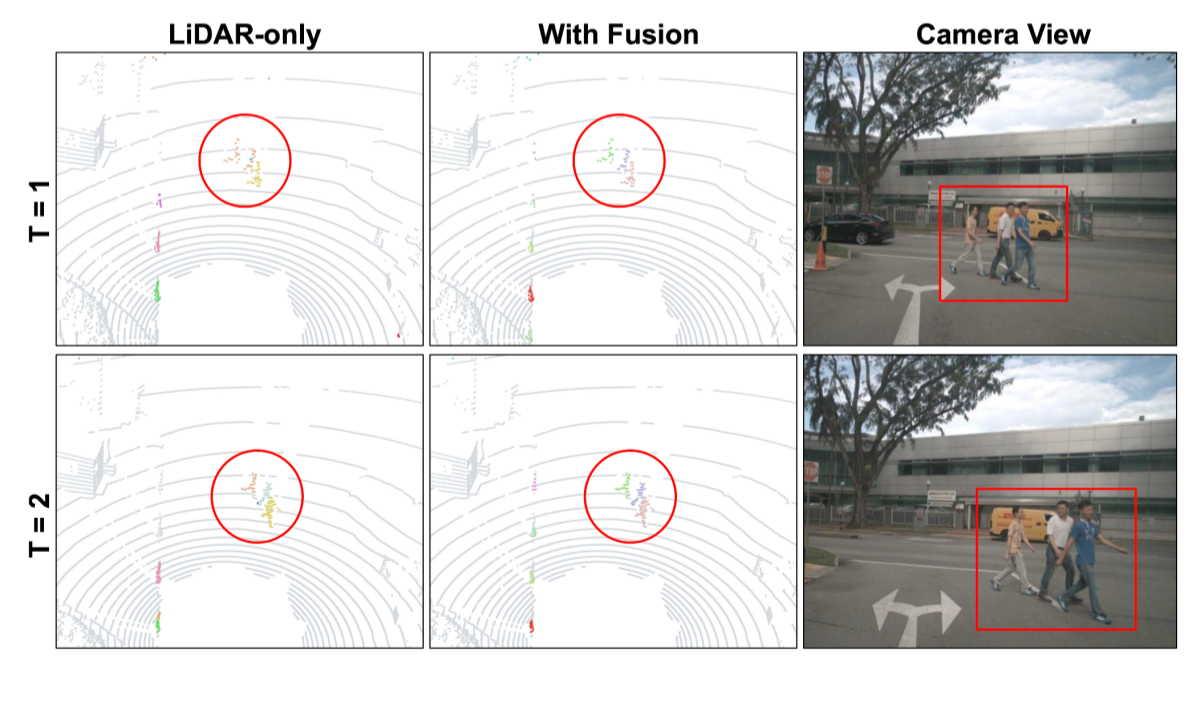
For a more detailed qualitative comparison against our LiDAR-only baseline without camera inputs, below we visualize the model predictions and highlight the failure modes. The baseline (1st column) wrongly segments the building at range as vegetation due to the limited information obtained from the LiDAR input. By contrast, our model with fusion (2nd column) effectively leverages the rich contextual information from the camera (highlighted by the red box) and segments the correct class.
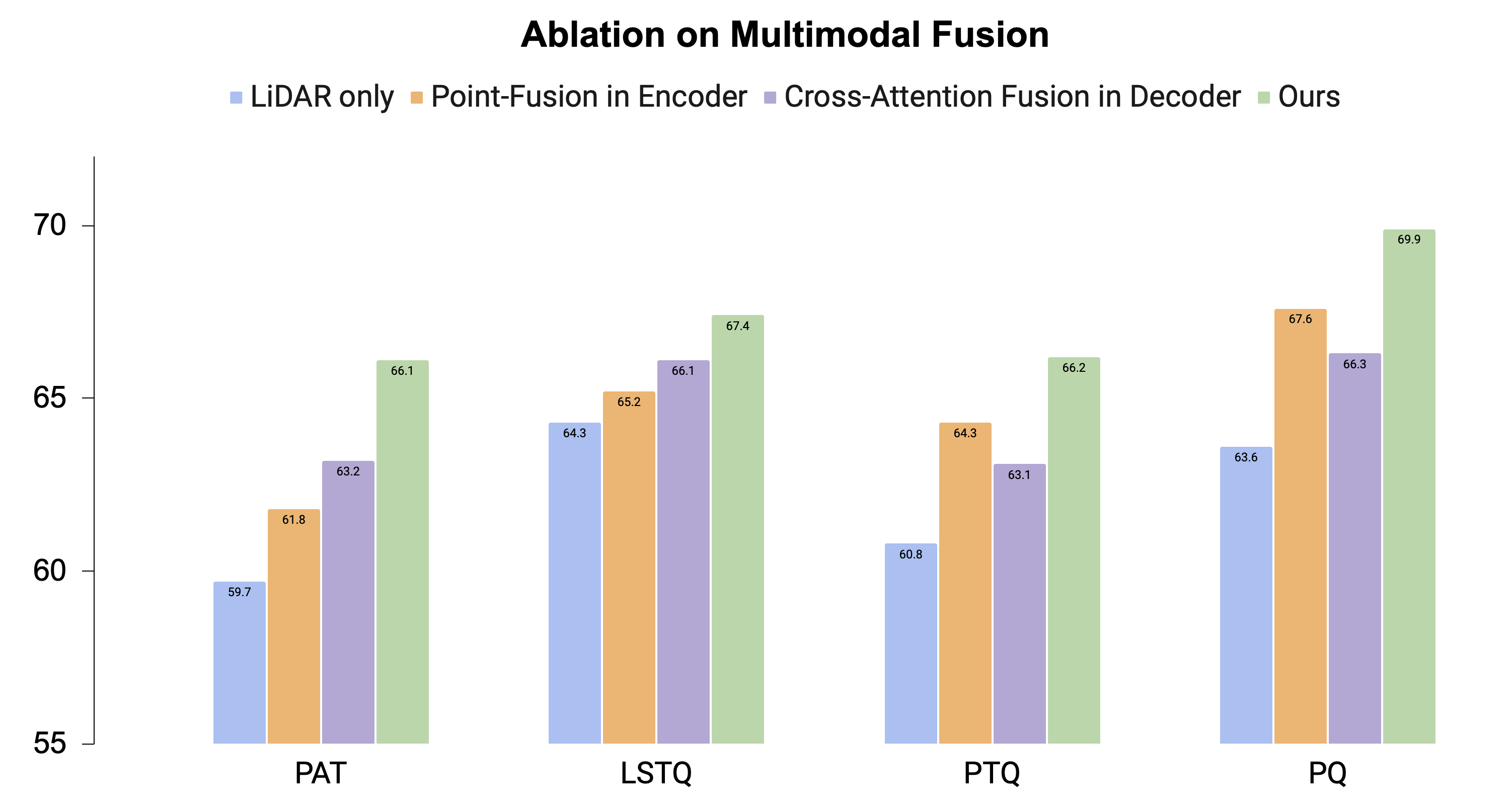
In the following scenario, we demonstrate substantial improvements in instance segmentation and tracking. The baseline (1st column) fails to track pedestrians when they are close to each other (the two pedestrians on the left are merged together as a single instance). By contrast, the camera view provides distinct appearance cues for each pedestrian, enabling our model to accurately segment and track them.
To further demonstrate the effectiveness of the proposed Tracklet Association Module (TAM), we conduct a comparison with tracking based on mask Intersection over Union (IoU) in the overlapping frames, a method commonly used in existing literature. For a fair comparison, both models are trained on the full nuScenes train split and evaluated on the validation split. The results presented below highlight the importance of using a learned temporal association mechanism with both spatial and appearance cues.
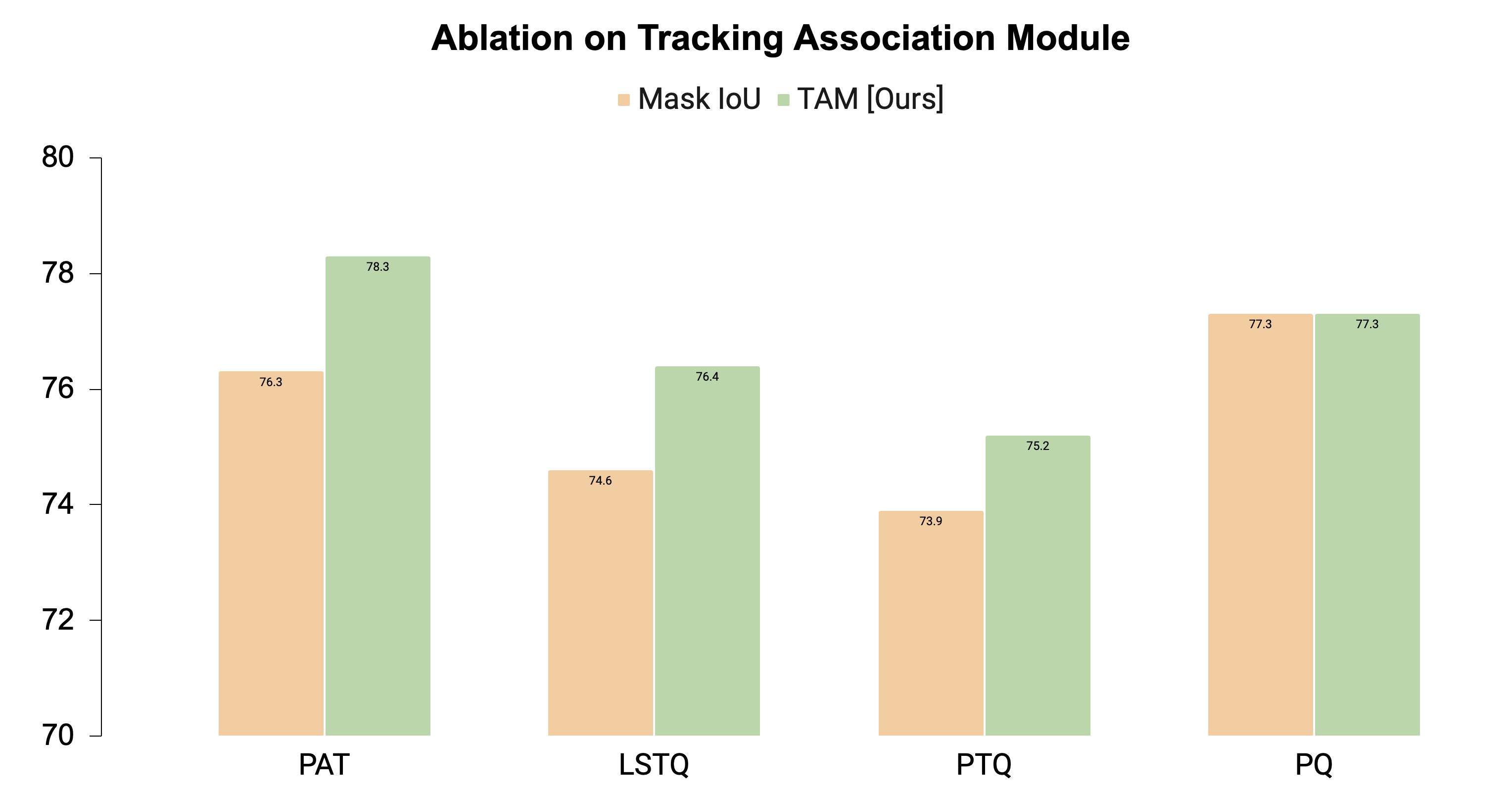
Conclusion
We proposed a novel, online approach for 4D panoptic segmentation which leverages both LiDAR scans and RGB images. We employ a transformer-based Panoptic Decoder which segments semantic classes and object tracklets by attending to scenes features from both modalities. Furthermore, our Tracklet Association Module (TAM) accurately associates tracklets over time in a learned fashion by reasoning over spatial and appearance cues. 4D-Former achieves state-of-the-art results on the nuScenes benchmark, thus demonstrating its efficacy on large-scale, real-world data. We hope our work will spur advancement in SDV perception systems, and encourage other researchers to develop multi-sensor methods for further improvement.
BibTeX
@InProceedings{athar20234dformer,
title = {4D-Former: Multimodal 4D Panoptic Segmentation},
author = {Athar, Ali and Li, Enxu and Casas, Sergio and Urtasun, Raquel},
booktitle = {Proceedings of the 2023 Conference on Robot Learning},
year = {2023},
}