Video
Training Data for Learning Driving Policies
Motivation
Large-scale data is crucial for learning realistic and capable driving policies. However, most driving data that gets collected in the real world is repetitive and uninteresting. Curating and upsampling interesting cases is limited to the existing set of logs. And unlike internet data that is plentiful and cheap, naively scaling data collection to encounter more long tail scenarios is far more expensive and can be unsafe.
In this work we ask: How can we continue to scale training data without relying solely on real world collection?
Challenges
One existing approach is to allow policies to explore novel states using algorithms like reinforcement learning in simulation. However, because other actors typically drive normally, the resulting scenarios can still be uninteresting.
Another approach is to hand-design challenging synthetic scenarios, but this can be difficult to scale and realism may be lacking.
Adversarial optimization can be used to automatically generate challenging scenarios, but it’s unclear how to make sure that these are actually useful for training.
Method
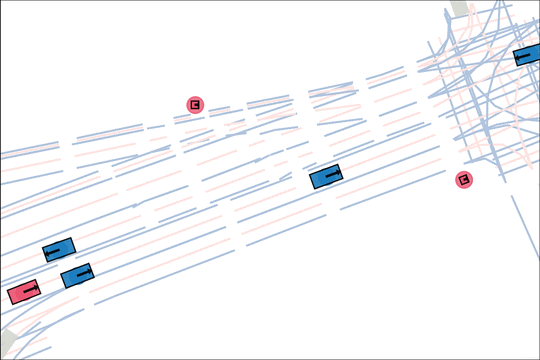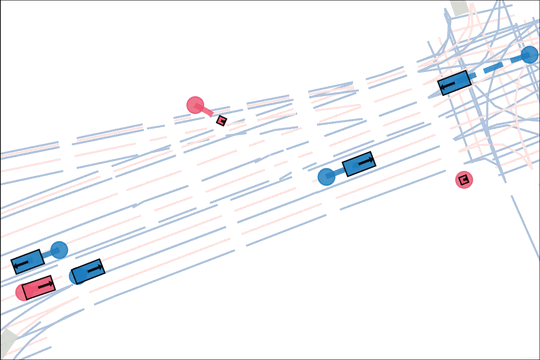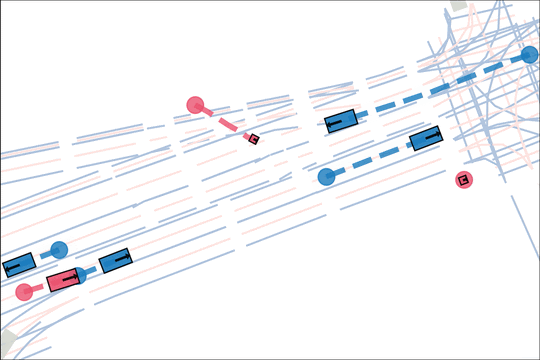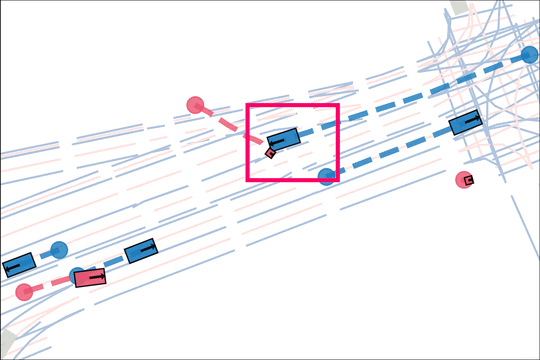
We design an asymmetric self-play mechanism where challenging, solvable and realistic scenarios automatically emerge from interactions between a teacher and student.
The teacher (red) aims to generate realistic scenarios where the student (blue) fails…
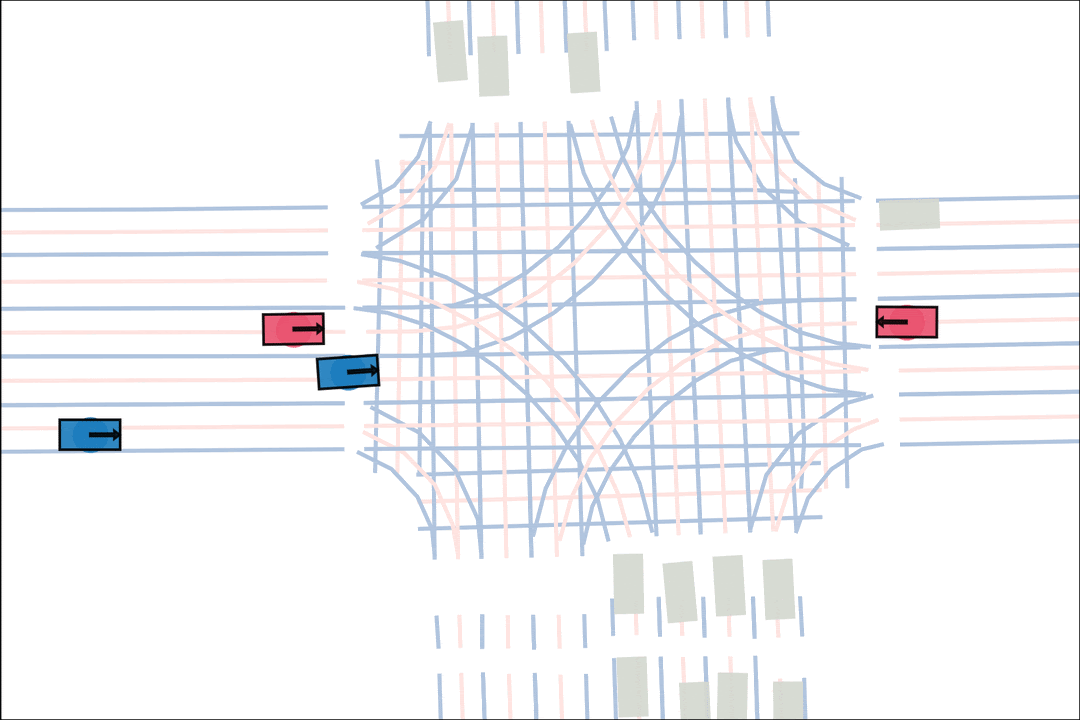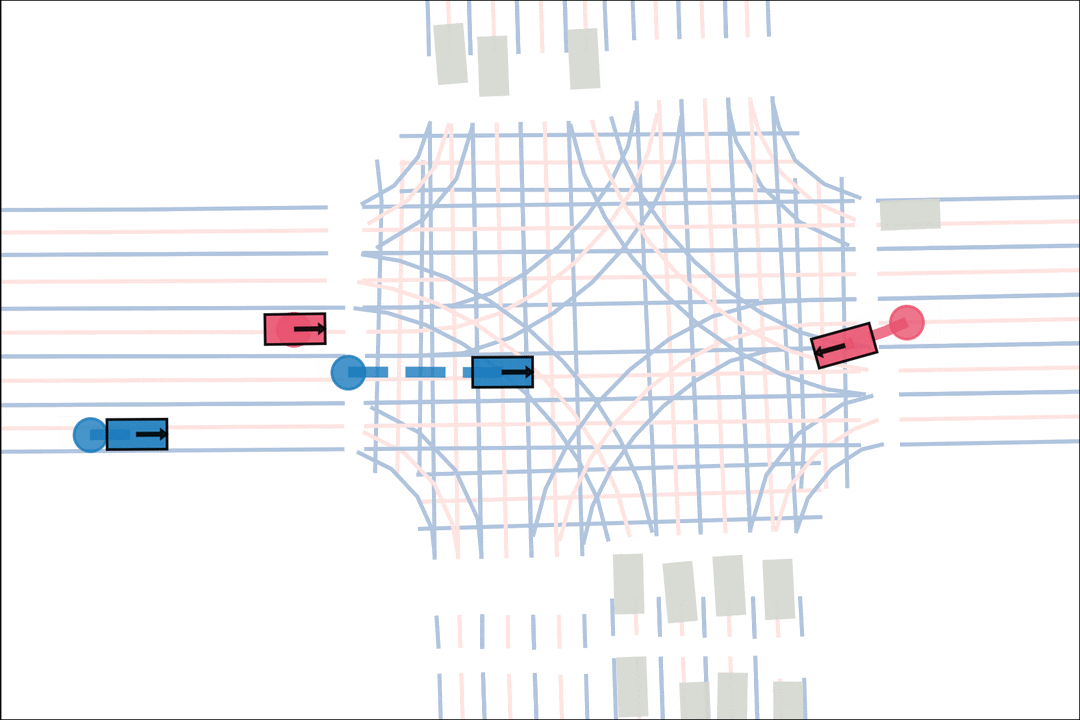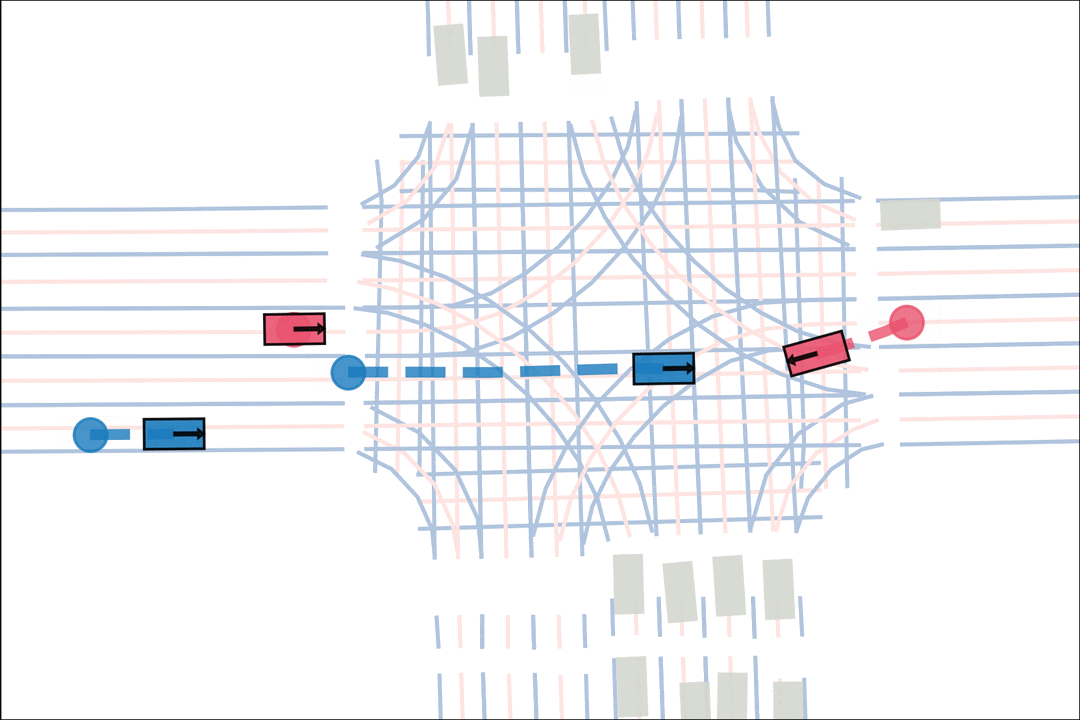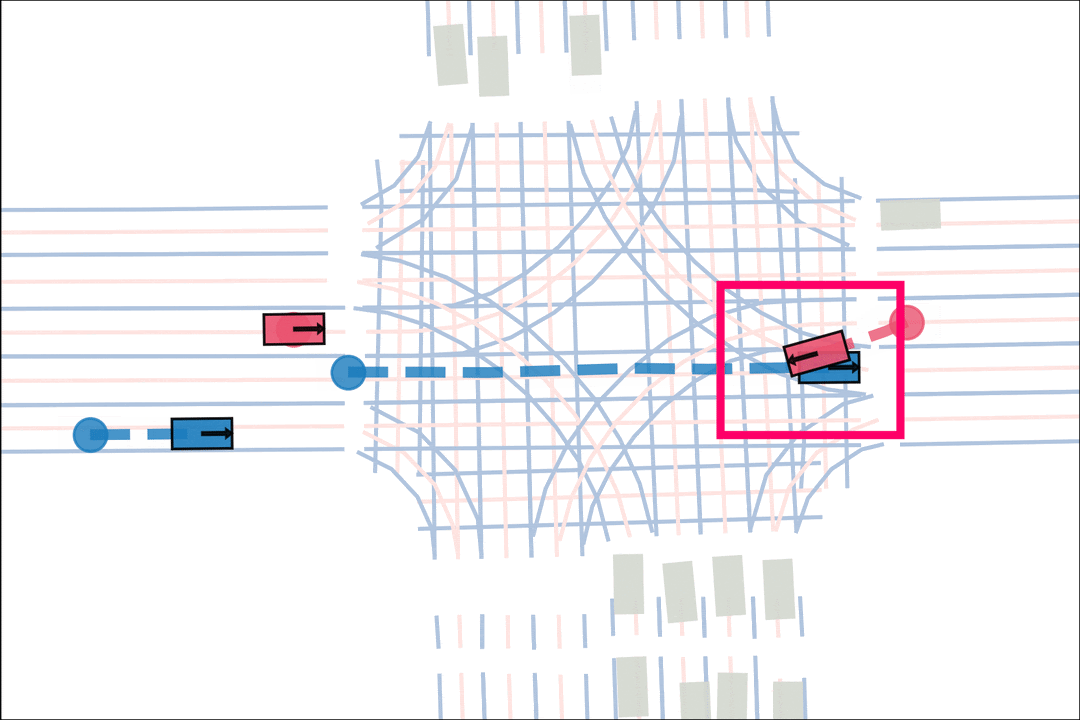
while trying to ensure that itself (green) can demonstrate a solution.
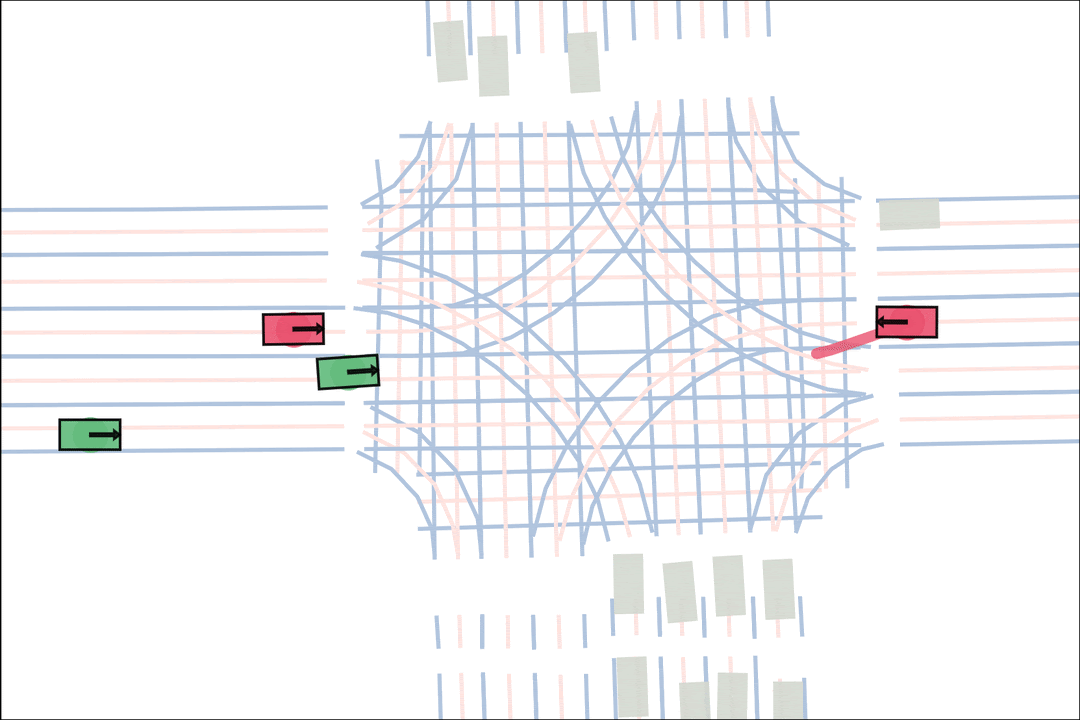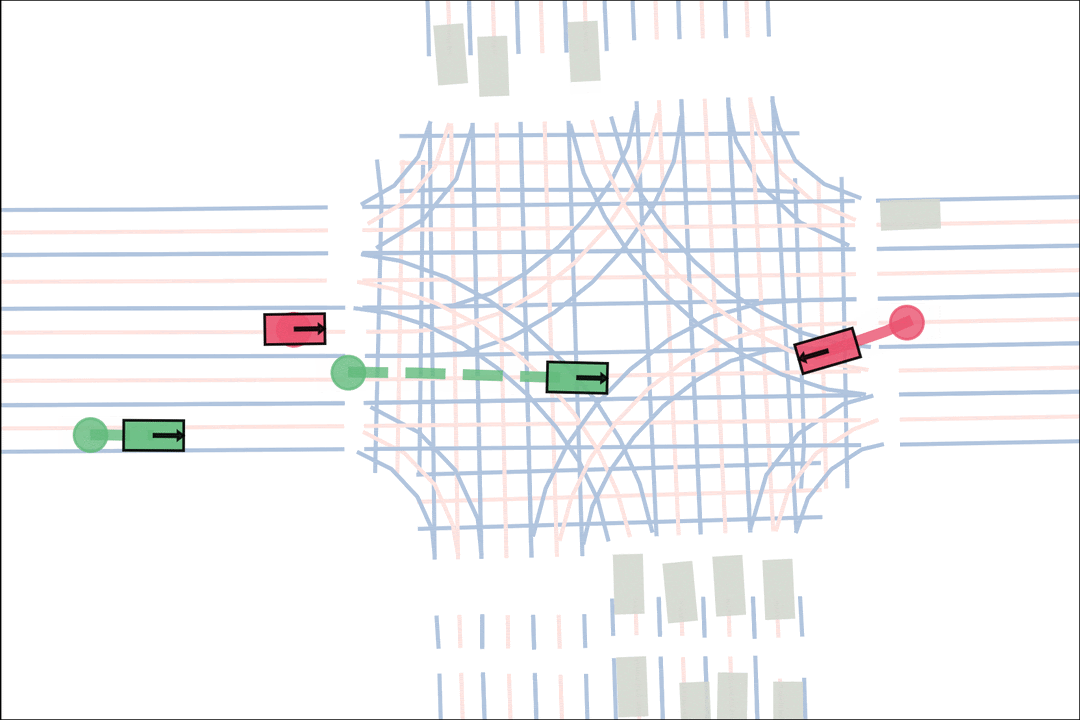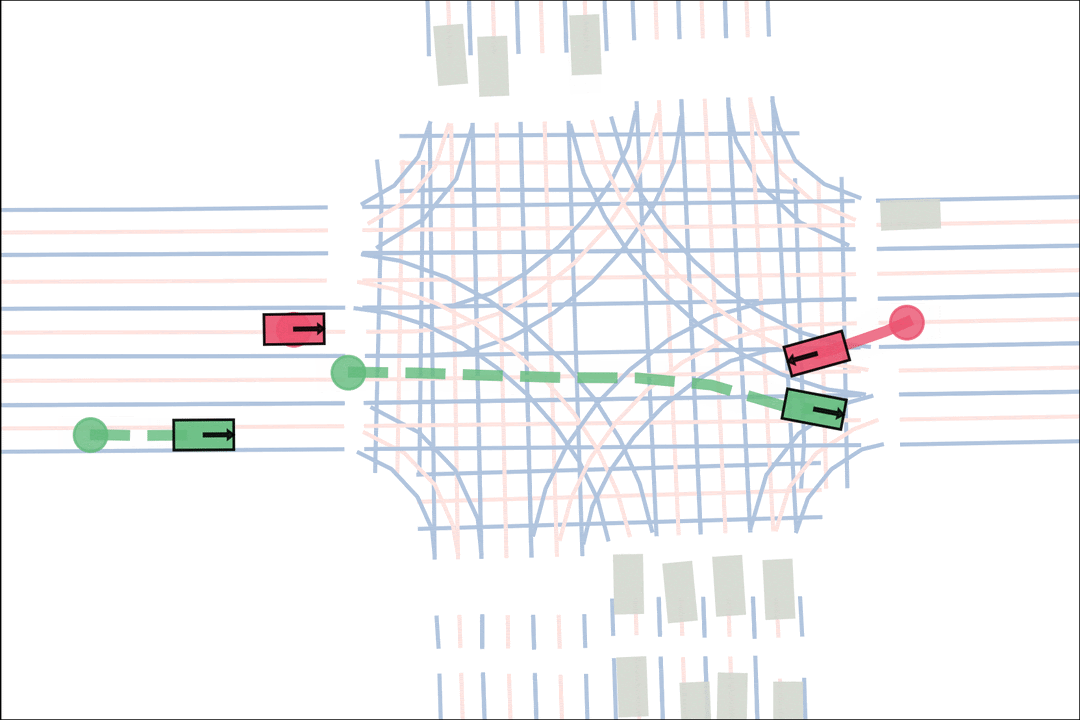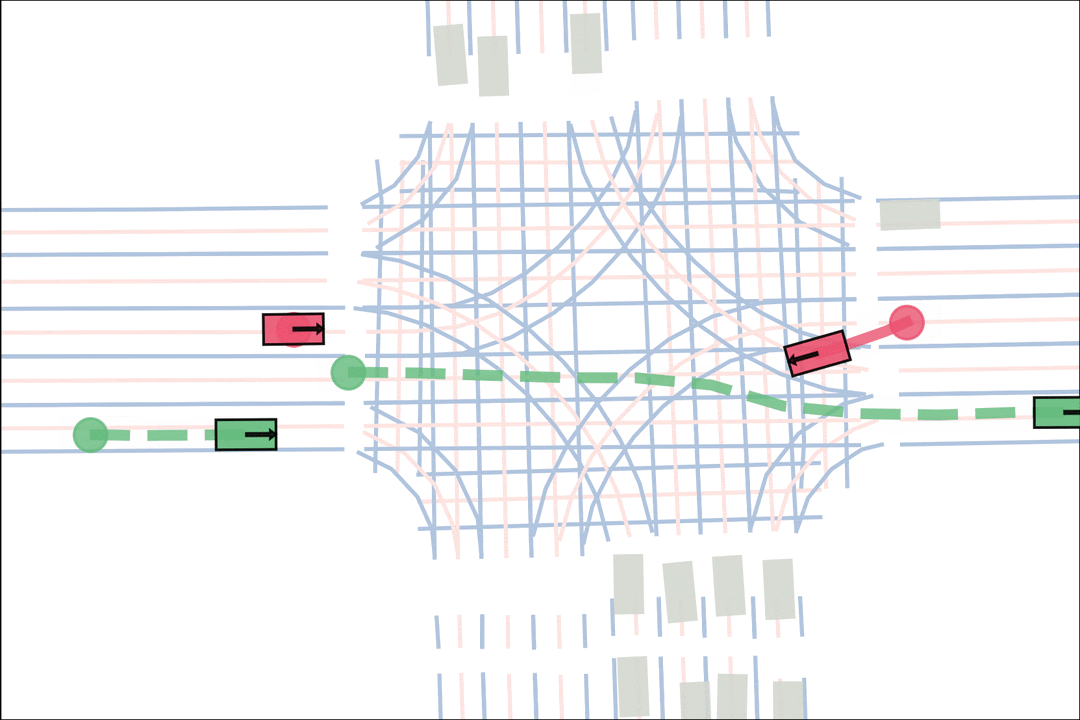
We sample an initial scene and designate adversarial actors at random. The teacher is rewarded by having adversarial actors collide with student-controlled actors but not teacher-controlled actors. The student is rewarded for avoiding all collisions. Adversarial actions are replayed to keep the scenario the same. All policies are regularized with real data to encourage more realistic scenarios.

Both policies interact and improve together, learning to generate and solve more and more scenarios
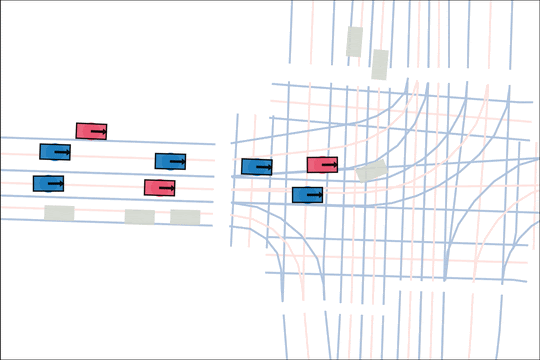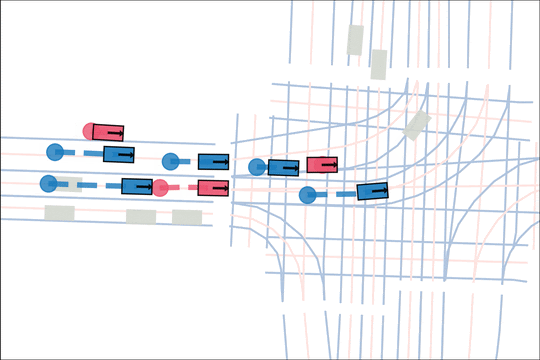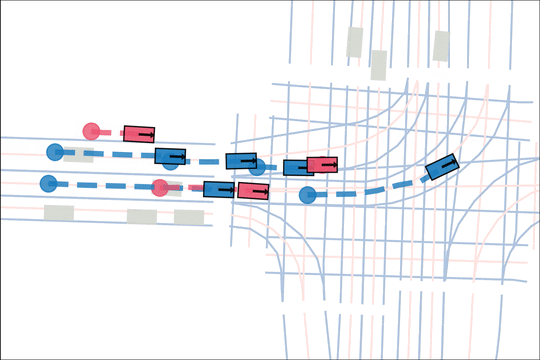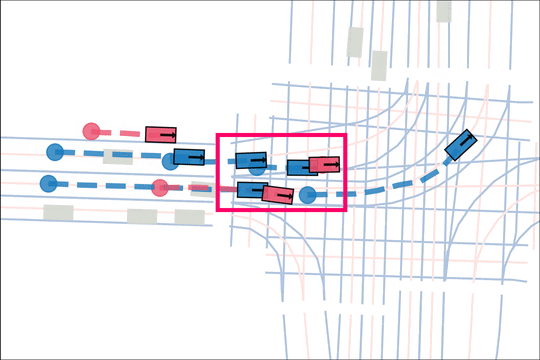
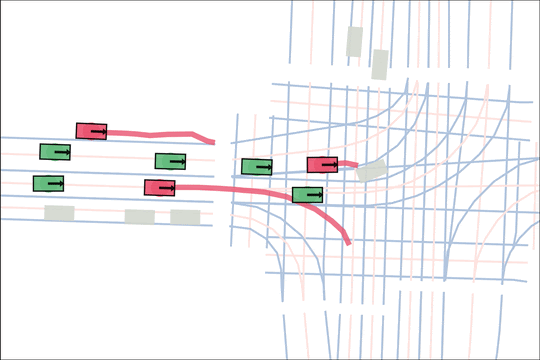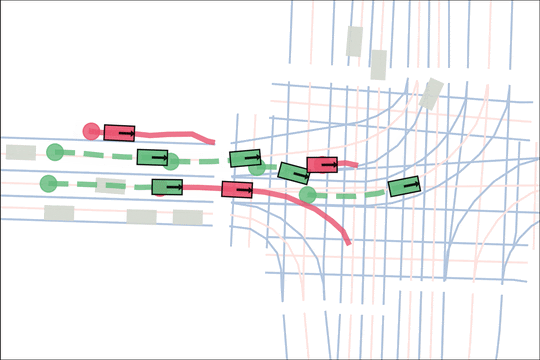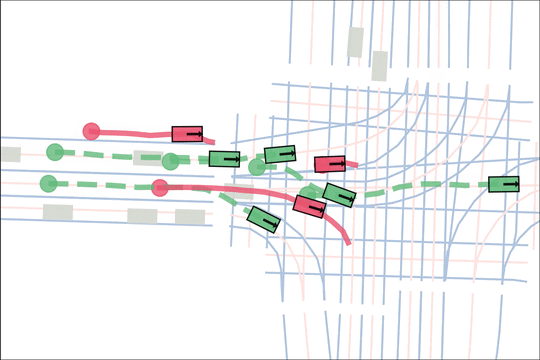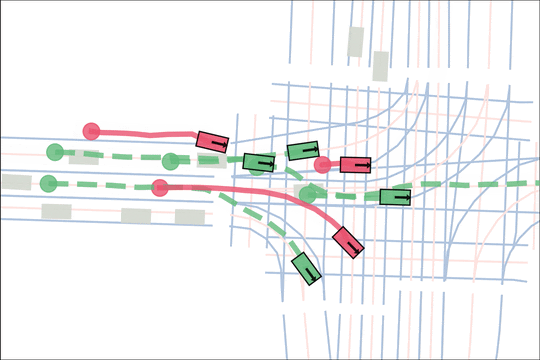
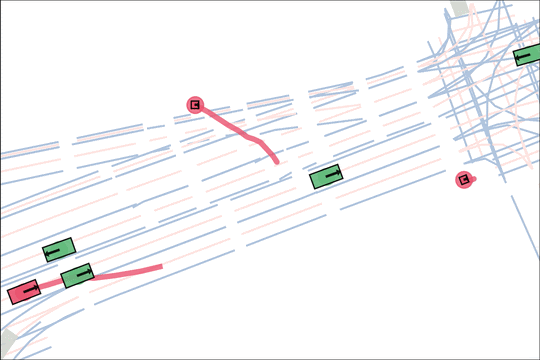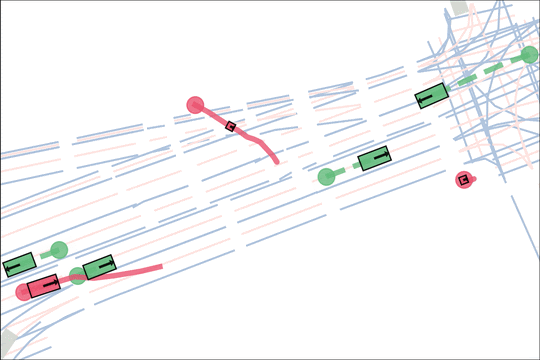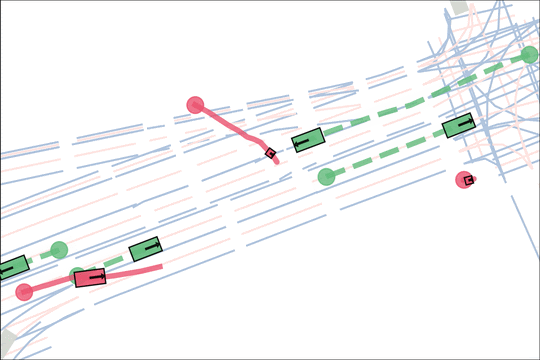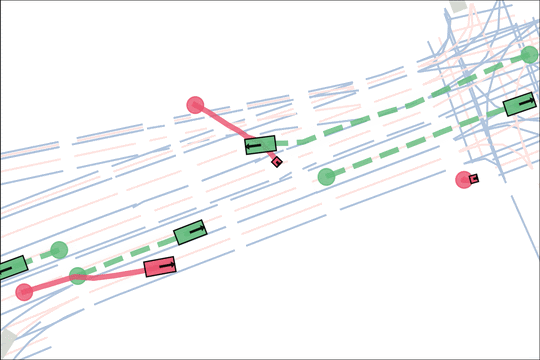
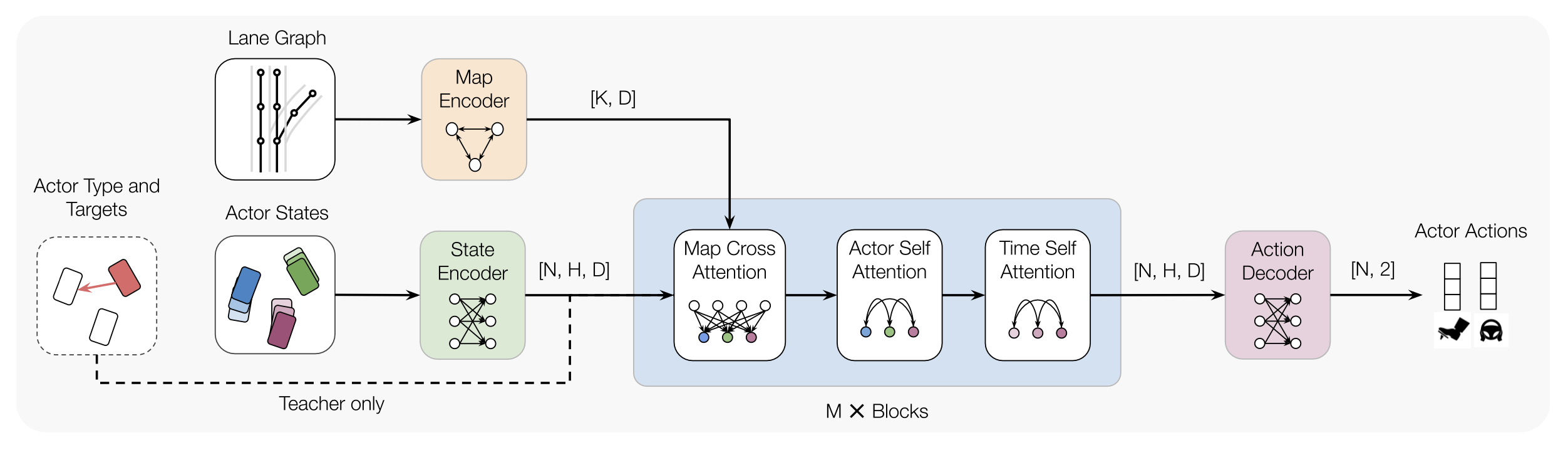
Architecture
We encode K lane graph nodes and state history for N actors over H history timesteps into D-dimensional features. A transformer backbone uses factorized attention to efficiently extract features before predicting steering and acceleration for all actors. The teacher policy additionally encodes whether an actor is adversarial, and if so who it should target.
Traffic Modeling
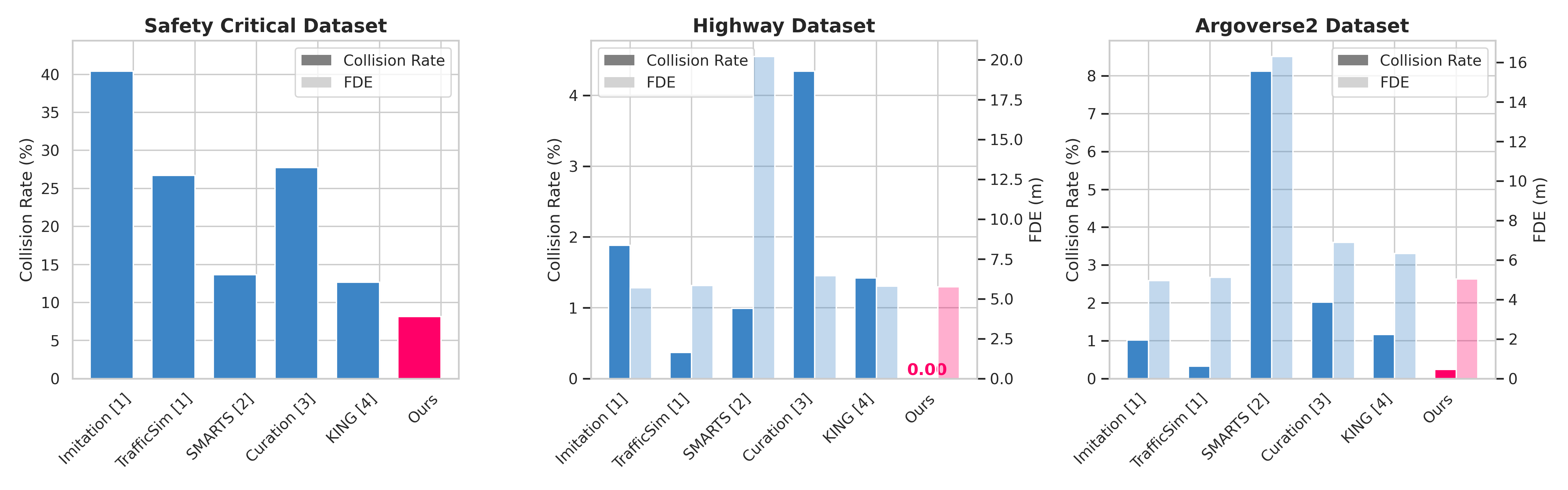
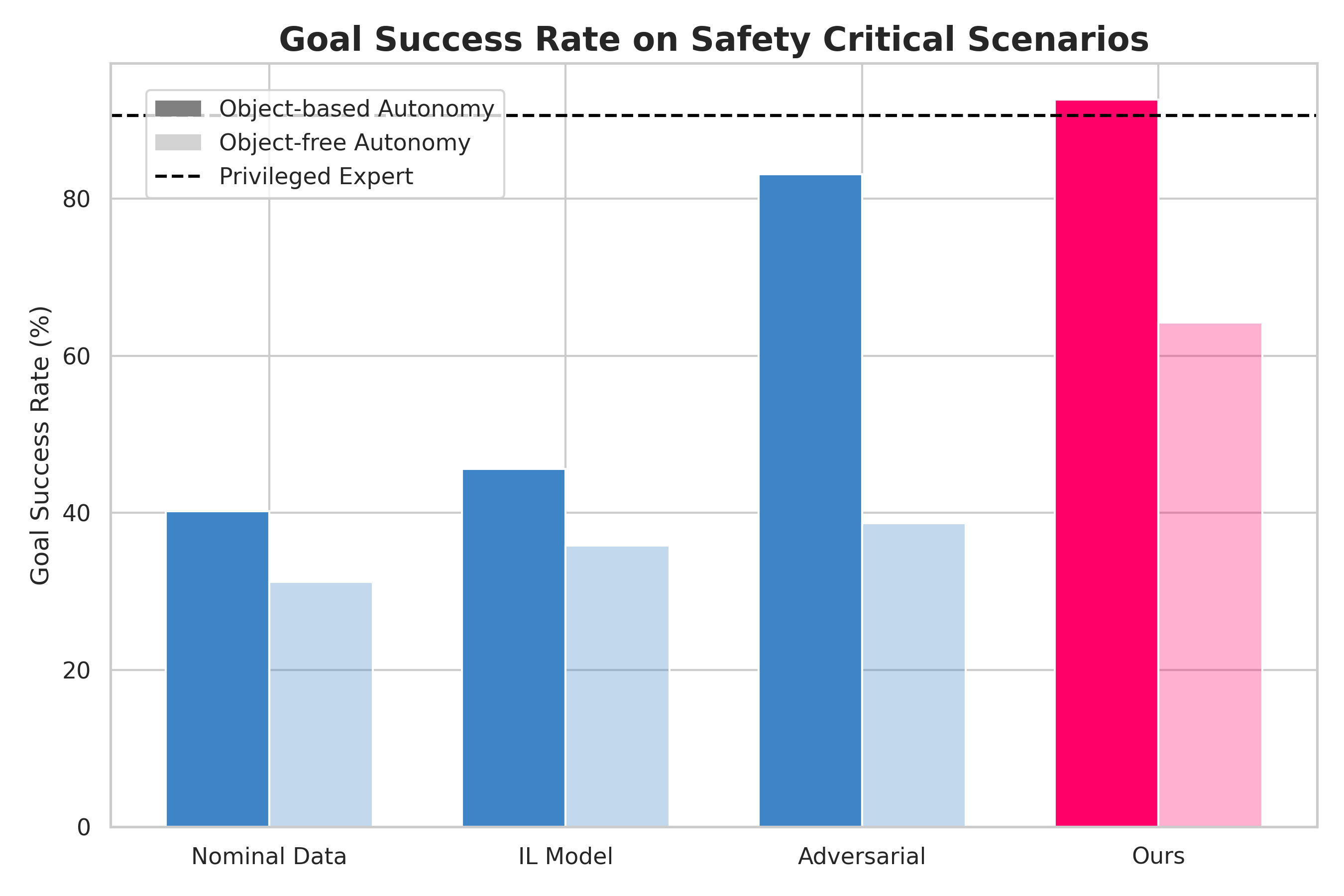
Quantitative Results
After training, the student learns a more realistic and robust policy compared to baselines while still maintaining realism.
Qualitative Examples
We show various qualitative comparisons against baselines on Argoverse2 below. Colored actors are controlled and grey actors are replayed.
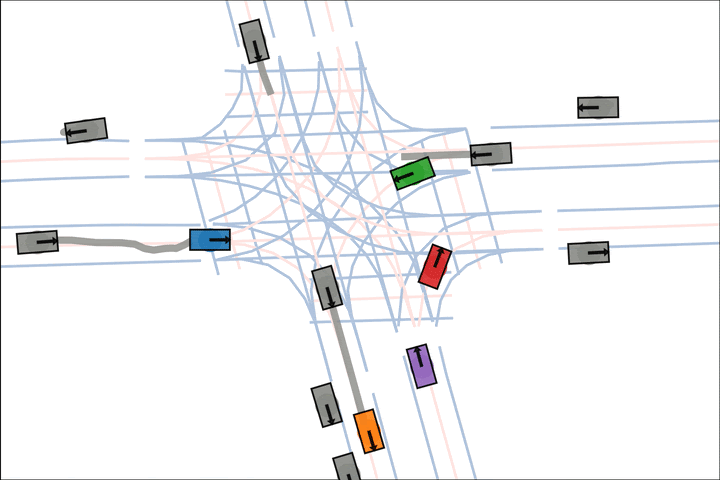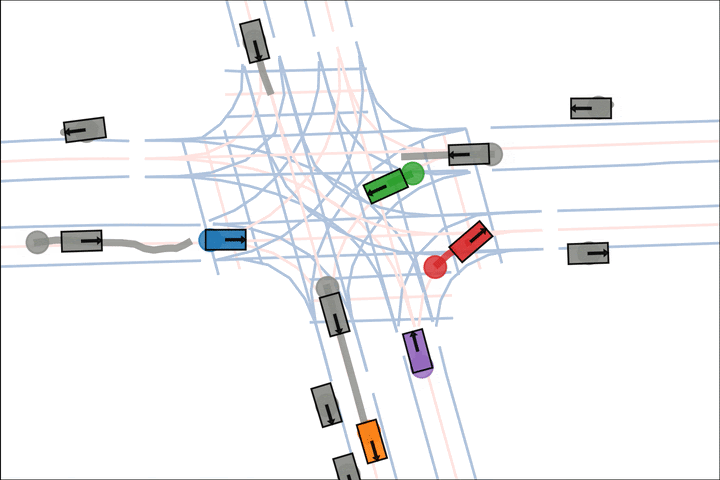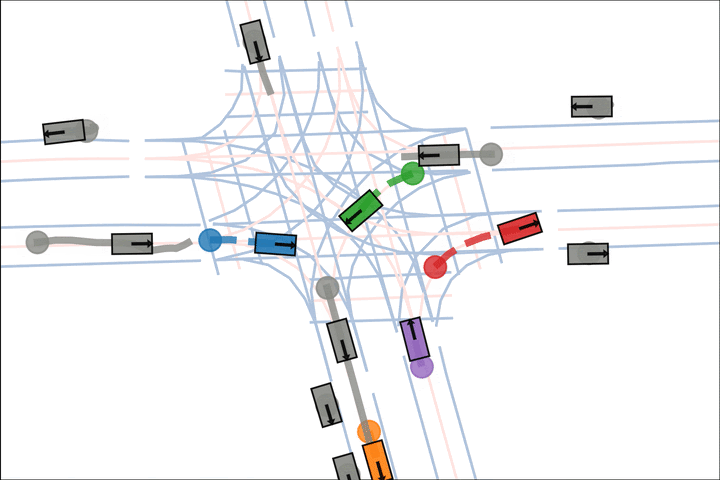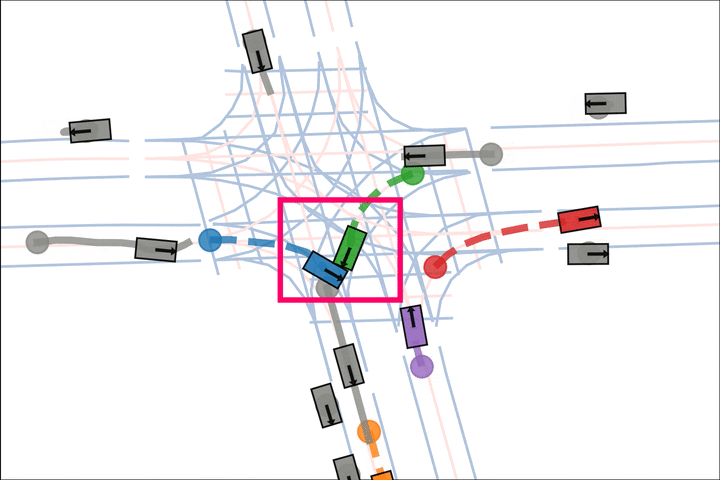
Baseline: The blue and green car fail to negotiate and collide.
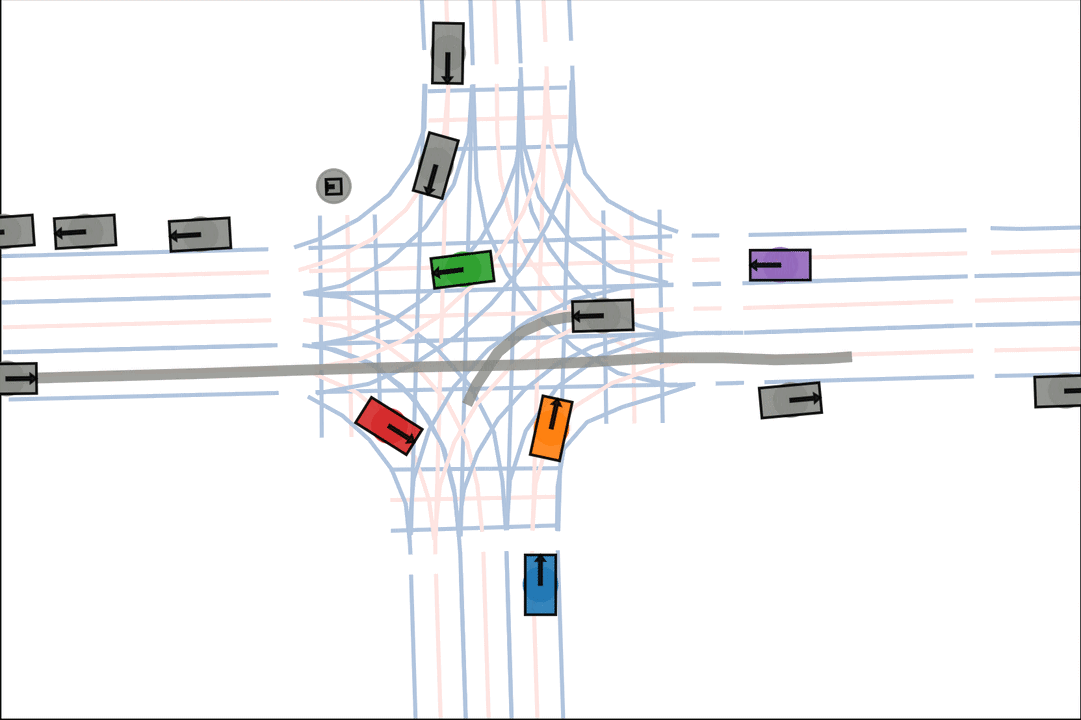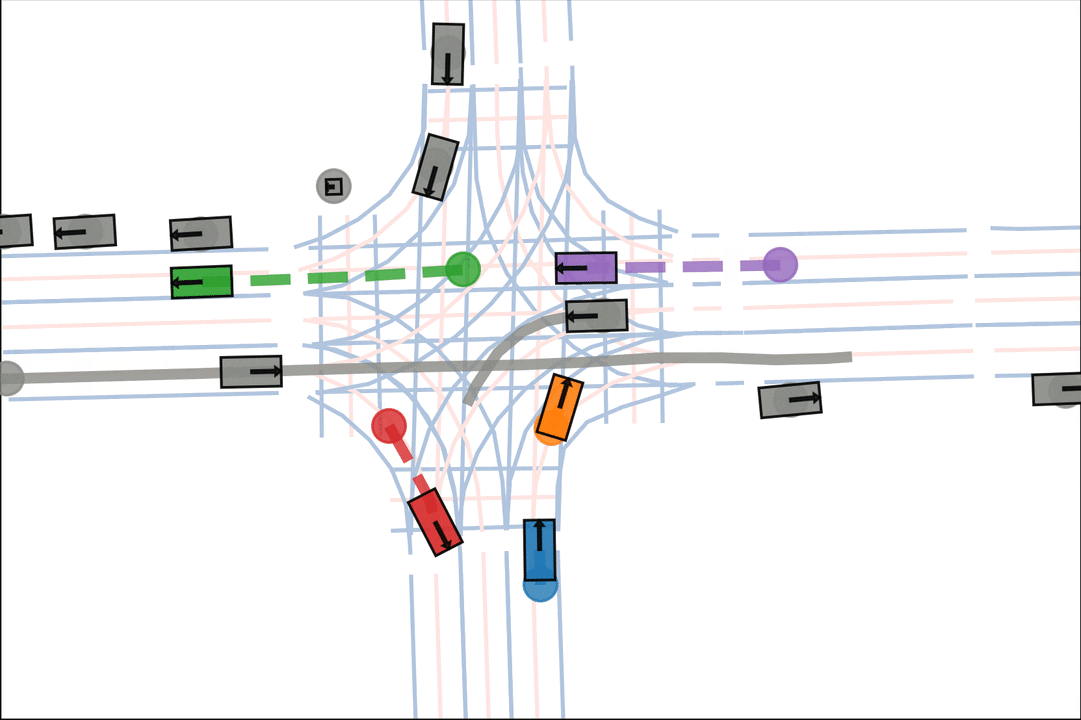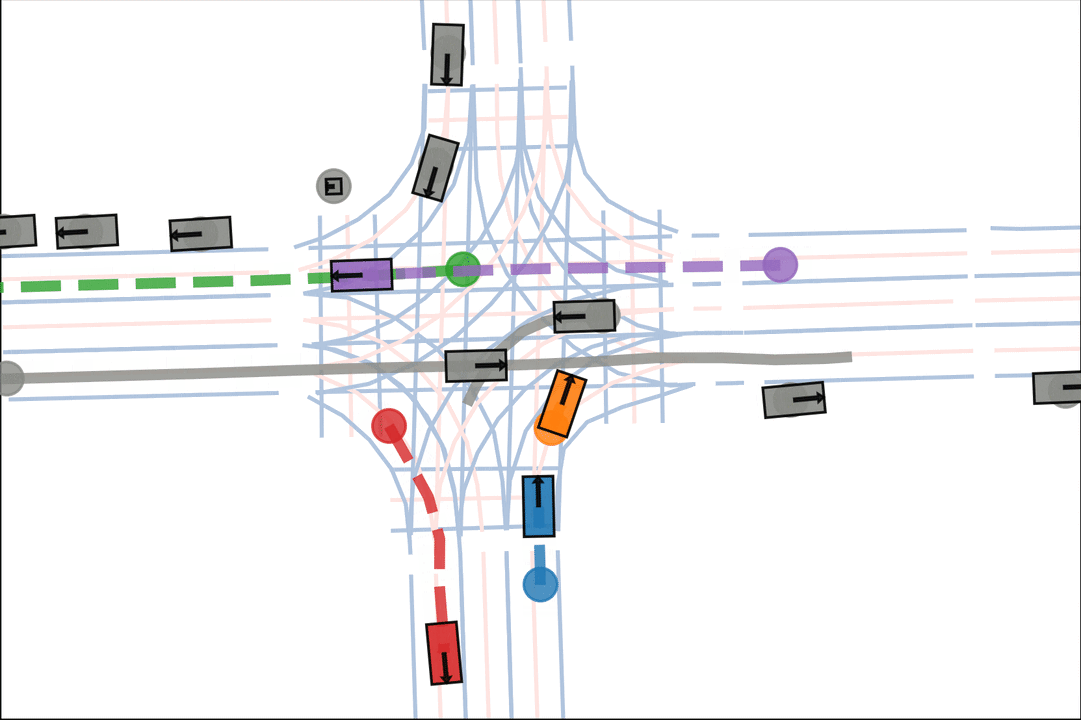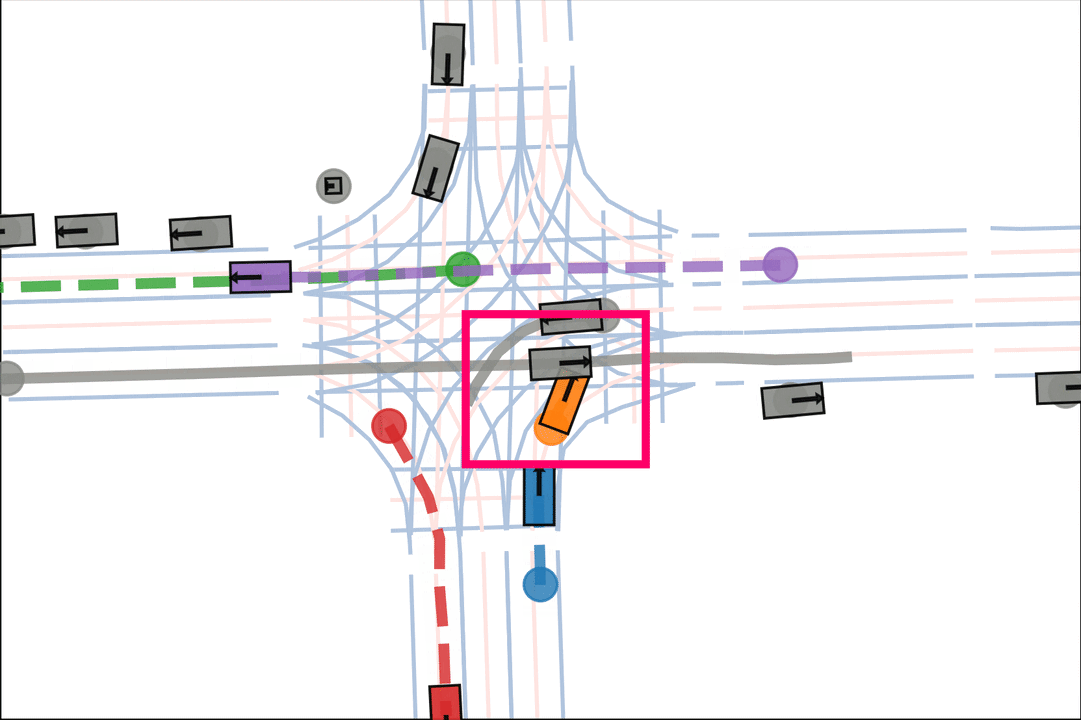
Baseline: The orange car is indecisive, leading to a collision.
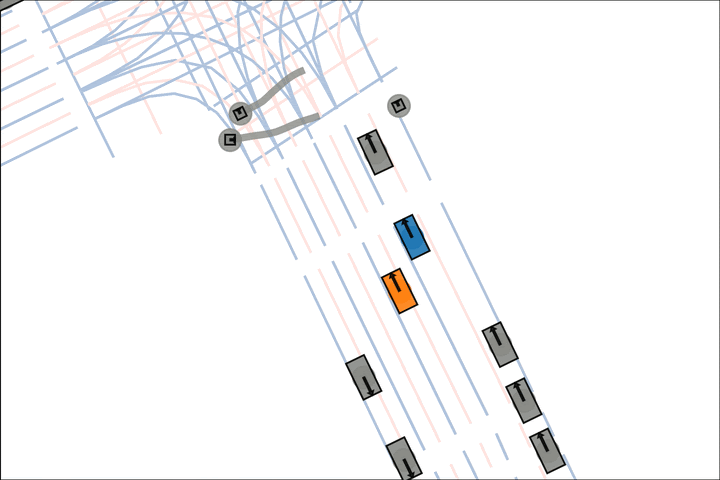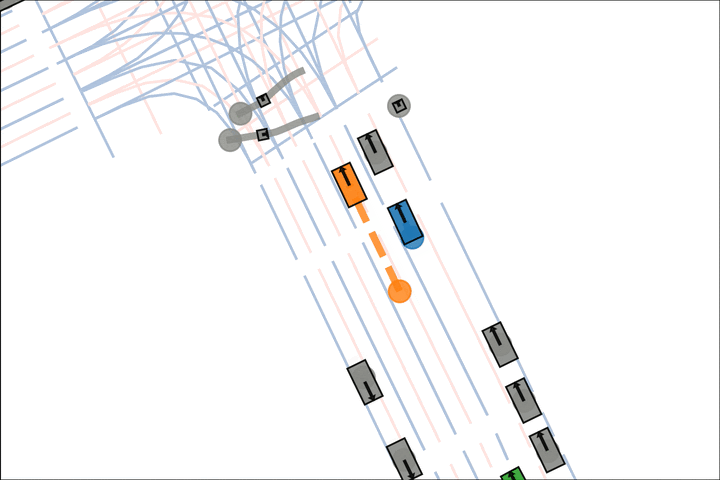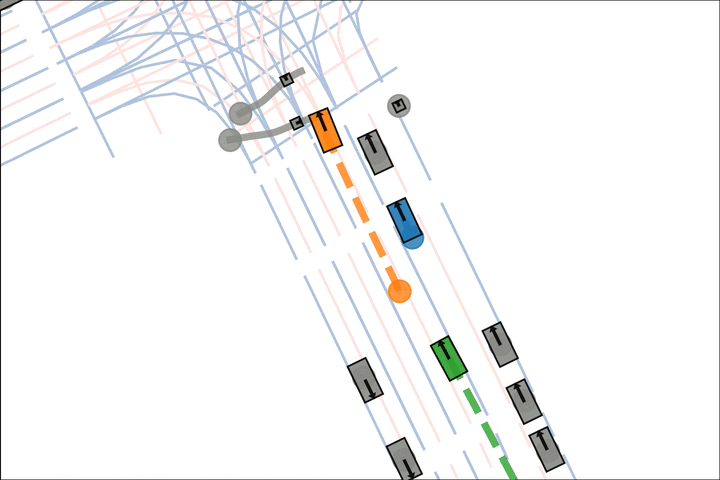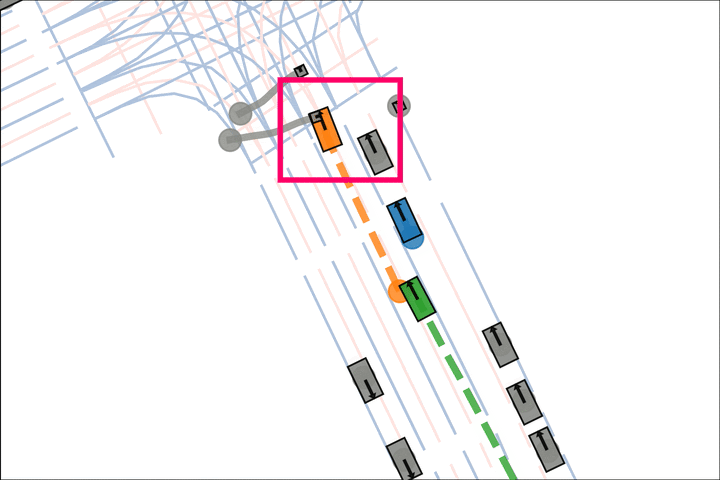
Baseline: The orange car pulls into the crosswalk.
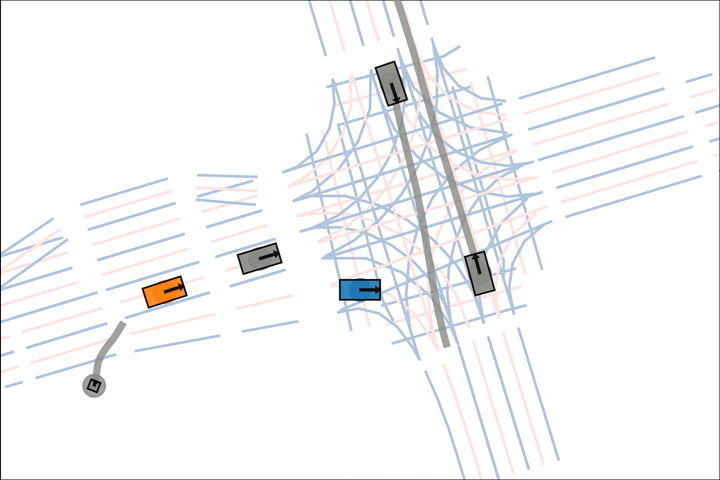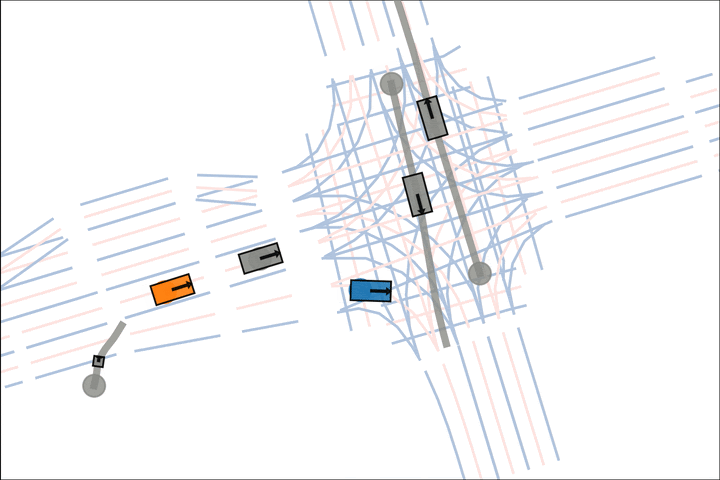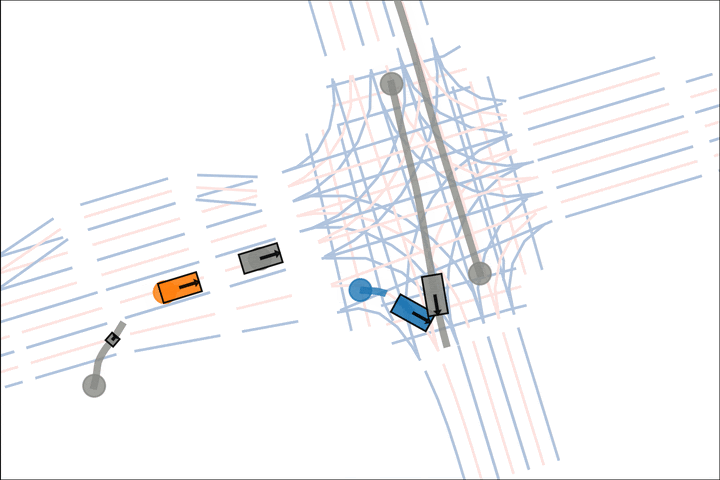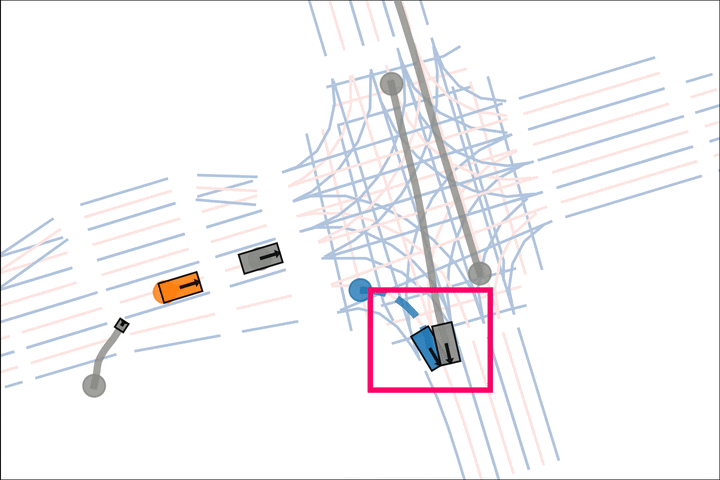
Baseline: The blue car fails to reason about the velocity of the grey car.
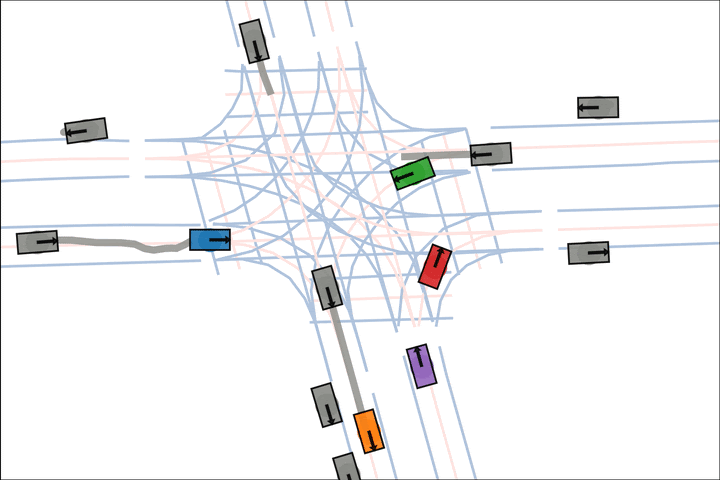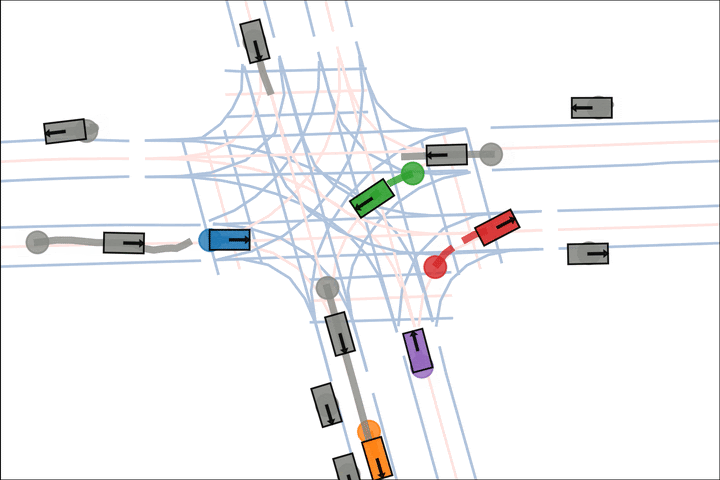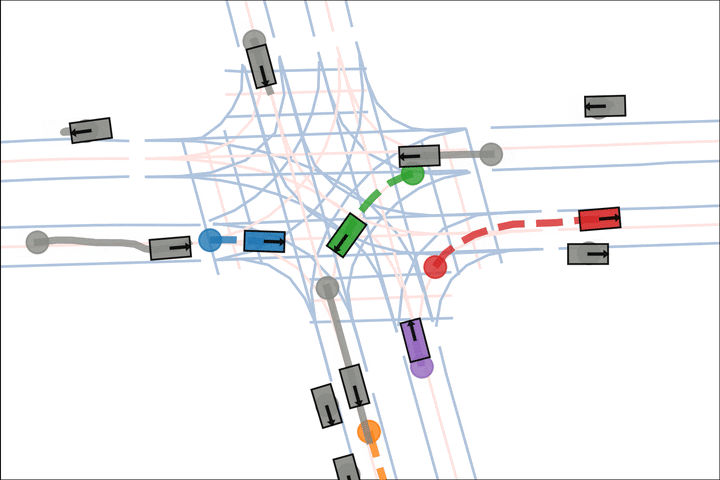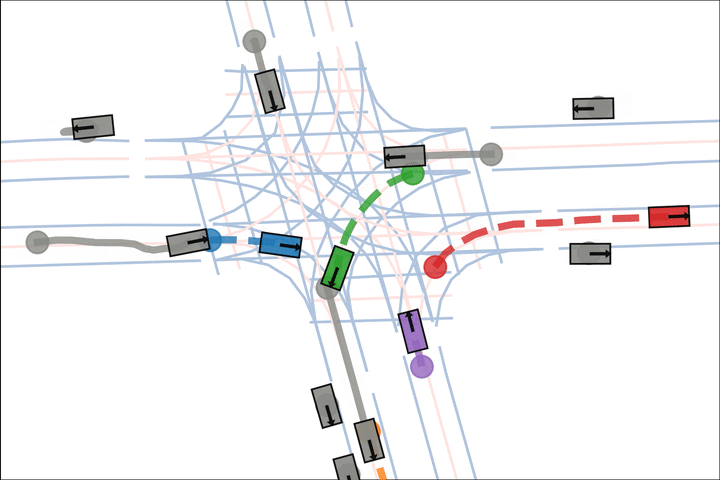
Ours: The blue car yields to the green car.
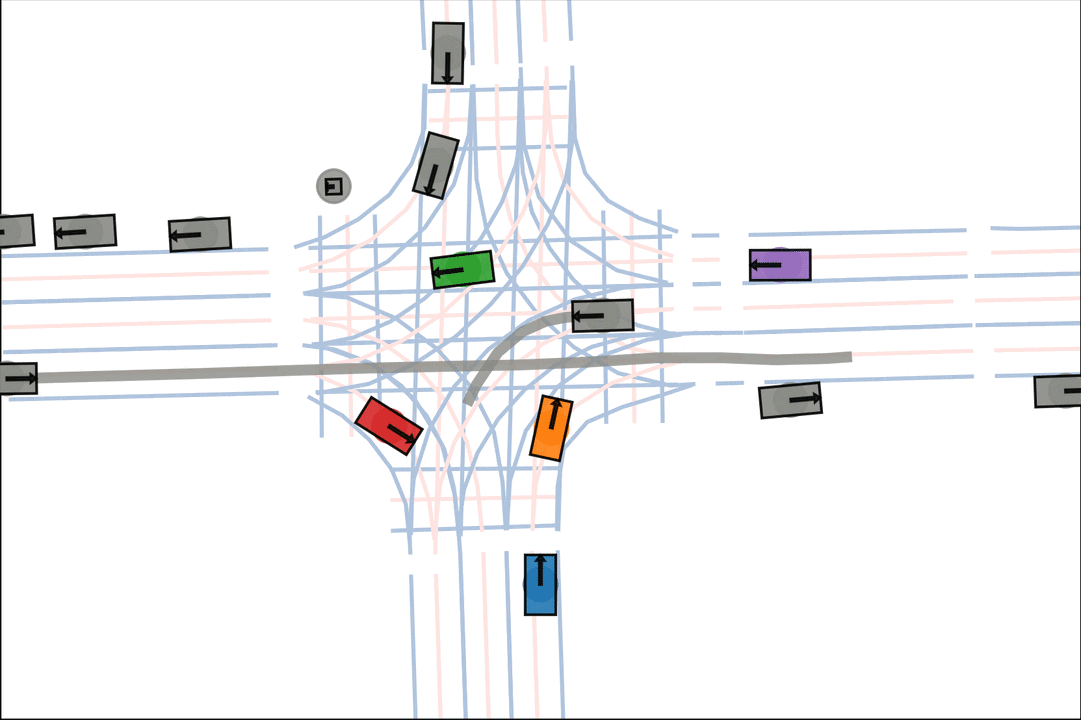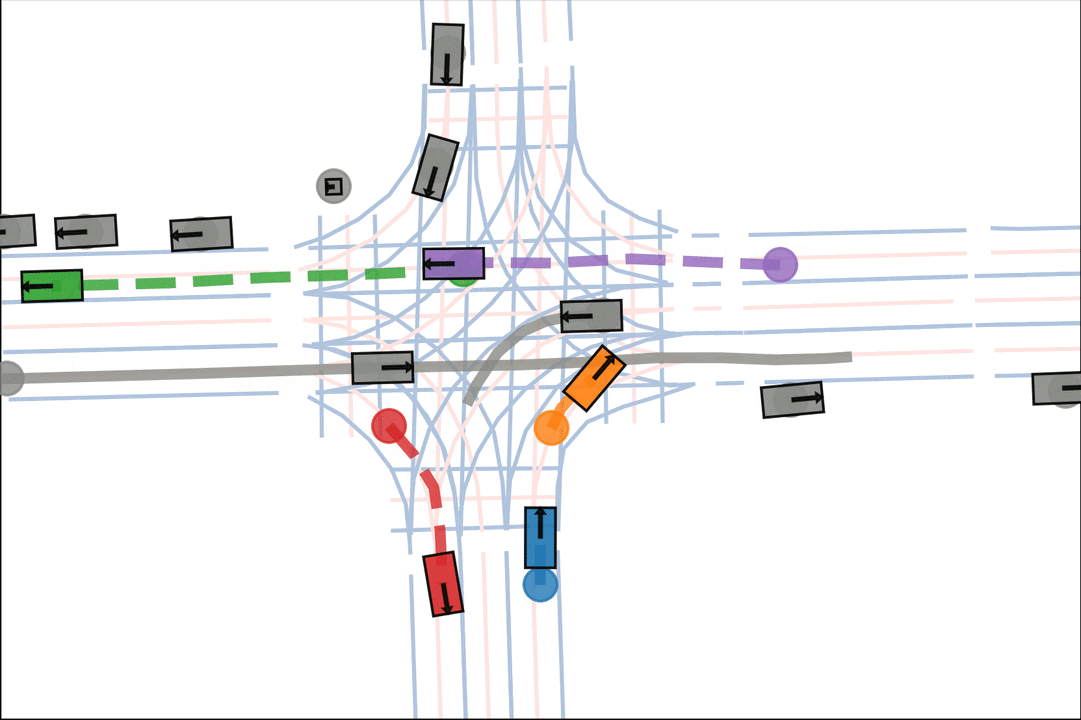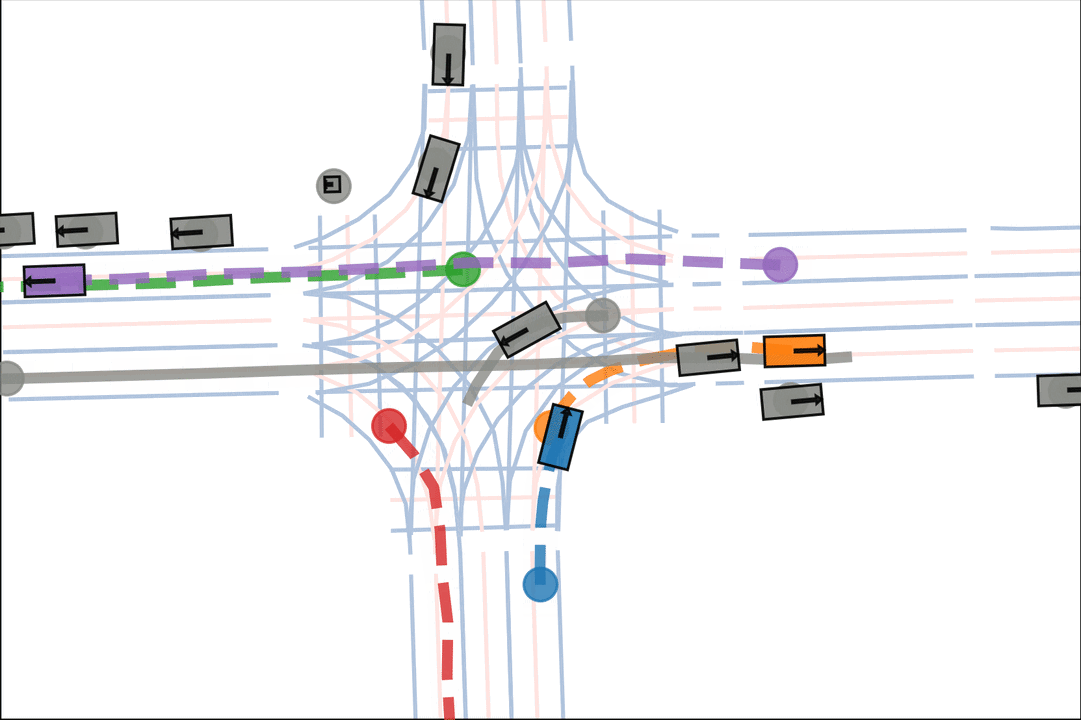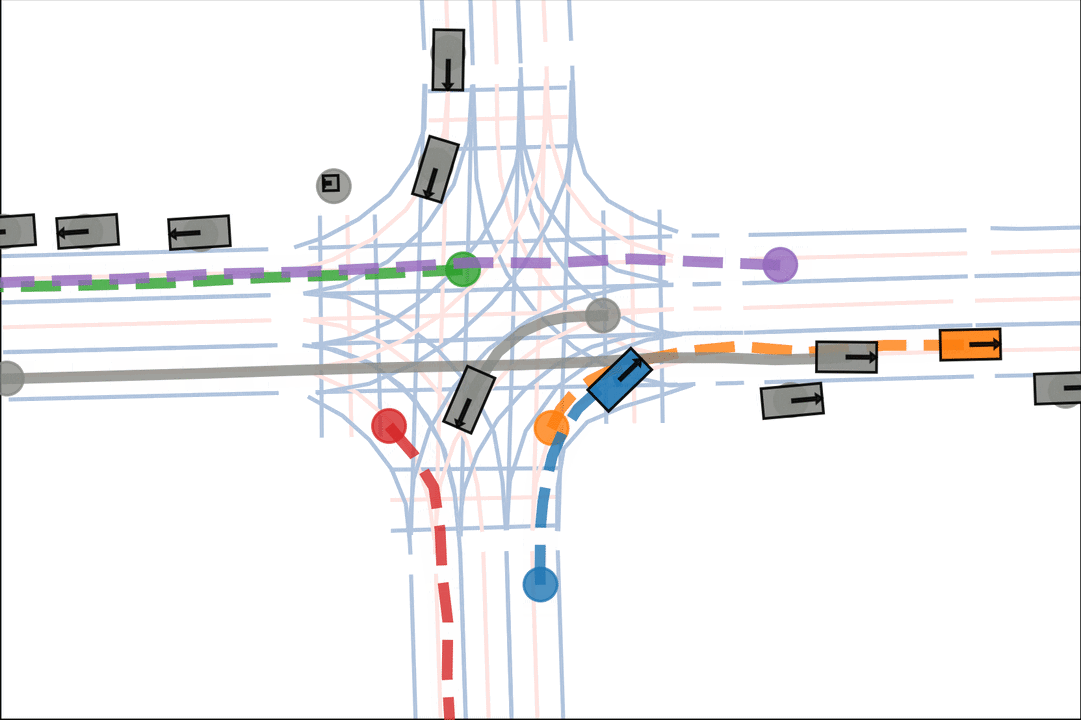
Ours: The orange car decisively turns after entering the intersection.
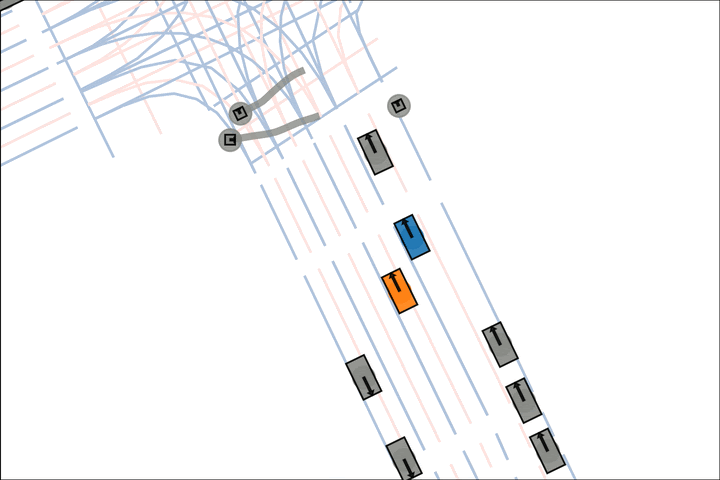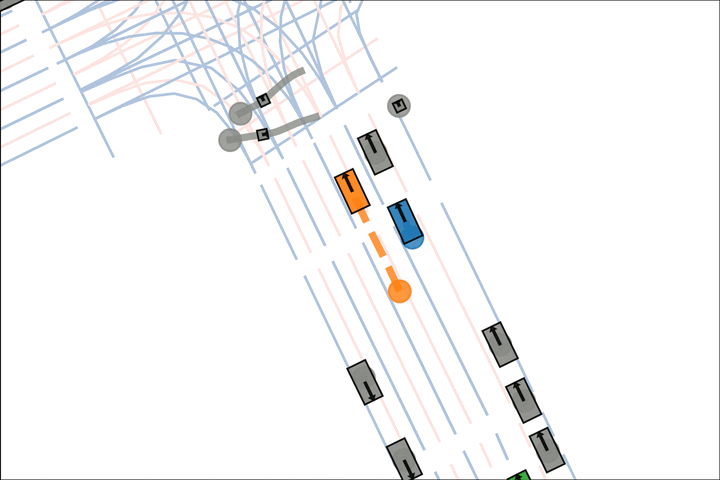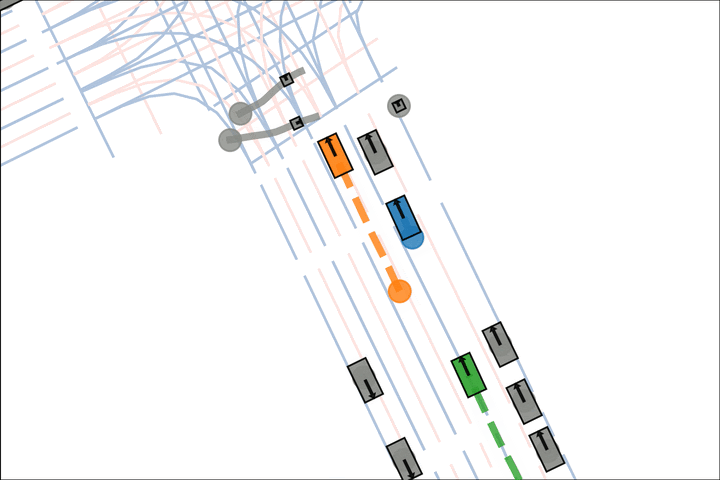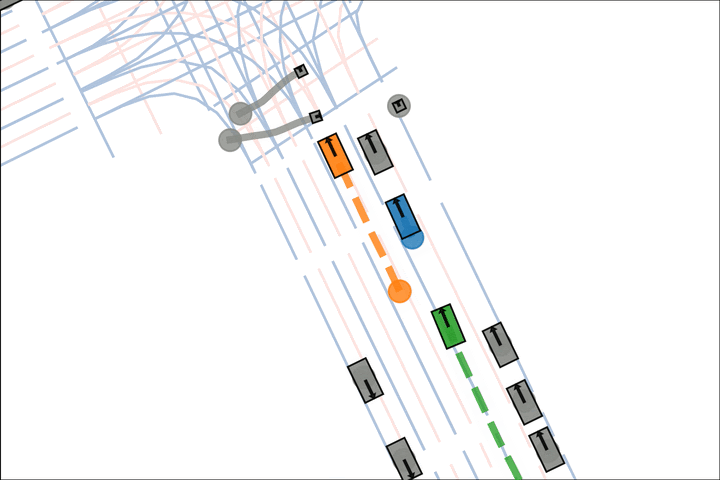
Ours: The orange car yields to the pedestrian.
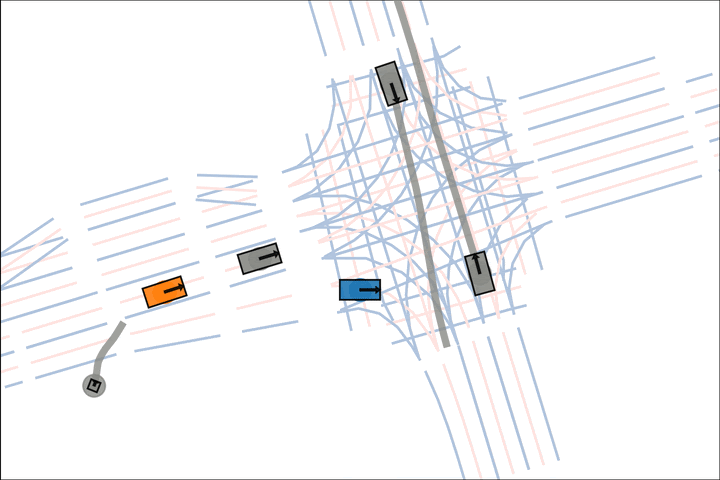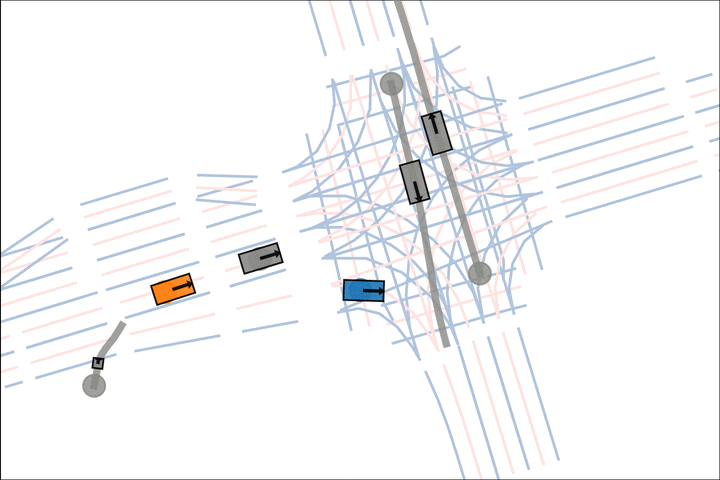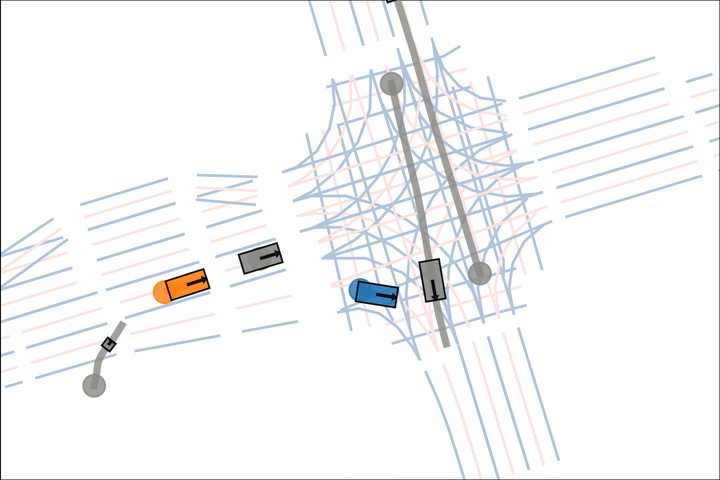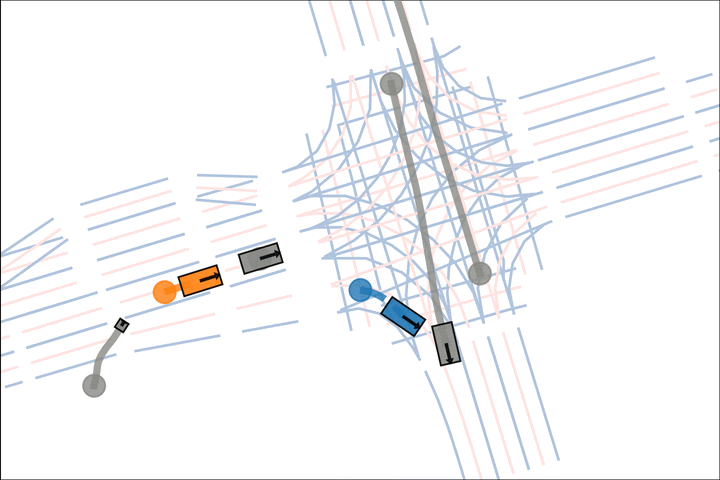
Ours: The blue car yields to the fast grey car.
End-to-End Autonomy
We’ve shown that self-play leads to a more robust student. Next, we evaluate the teacher’s ability to zero-shot generate scenarios for other policies. This allows us to first efficiently train the teacher at scale in lightweight simulation, before deploying it to interact with an end-to-end policy using high fidelity sensor simulation, without the need for expensive retraining.
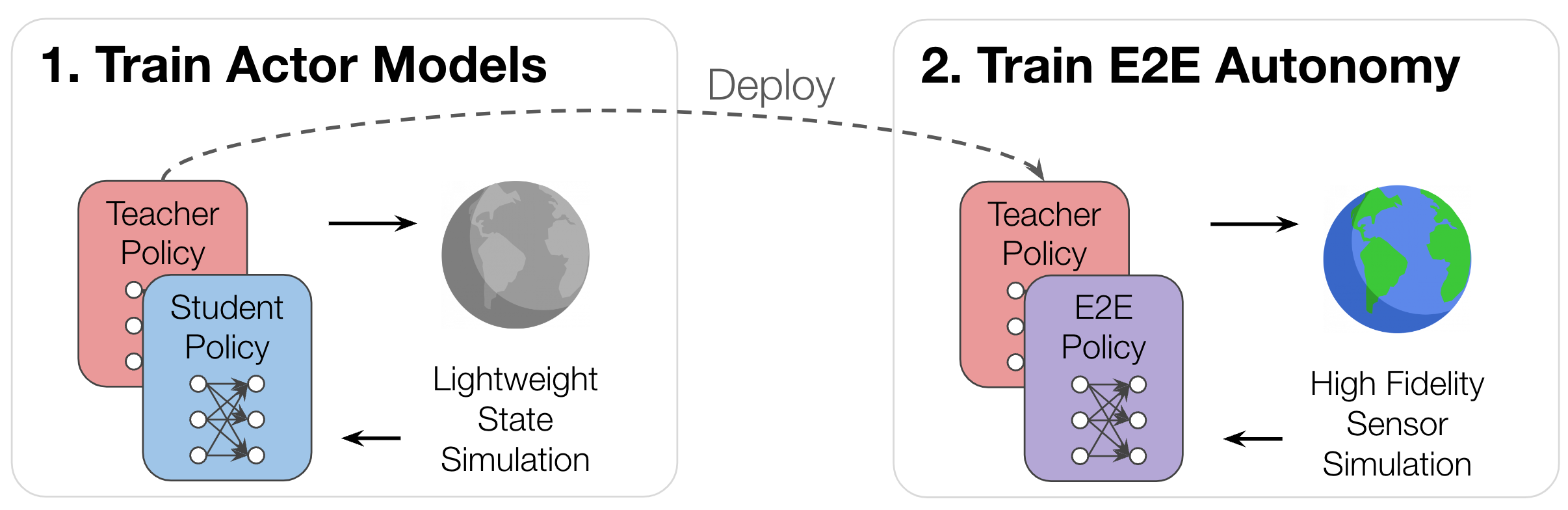
Our results show that training using scenarios generated with asymmetric self-play leads to far more robust policies across different autonomy paradigms.
Qualitative Examples
We compare against an autonomy model that was trained only on real data.
Baseline: Autonomy does not react to cut-in early enough.
Baseline: In a merge scenario, autonomy does not negotiate with merging actor, becoming uncomfortably close to rear ending them.
Ours: Autonomy quickly brakes, avoiding collision.
Ours: Here autonomy appropriately adjusts speed to gently slow down for the merging actor.
Conclusion
We have presented an asymmetric self-play approach for learning to drive, where solvable and realistic scenarios naturally emerge from the interactions of a teacher and student policy. We have shown that the resulting student policy can power more realistic and robust traffic simulation agents across several datasets, and the teacher policy can zero-shot generalize to generating scenarios for unseen end-to-end autonomy policies without needing expensive retraining. While the results are promising, we recognize some existing limitations. Firstly, the specific type of scenarios the teacher finds is not controllable; incorporating advances in controllable traffic simulation or exploring alternative reward designs and training schemes to encourage diversity can be interesting directions to explore. Exploring alternative failure modes besides collision (e.g. off-road, unrealistic behaviors, perception failures) is another promising avenue for future work
BibTeX
@inproceedings{zhang2024learning,
title = {Learning to Drive via Asymmetric Self-Play},
author = {Chris Zhang and Sourav Biswas and Kelvin Wong and Kion Fallah and Lunjun Zhang and Dian Chen and Sergio Casas and Raquel Urtasun},
booktitle = {Computer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024},
year = {2024},
} 