
Overview
MemorySeg learns a 3D latent memory representation for better contextualizing online observations. Here’s an example of the learned memory visualized after applying PCA.
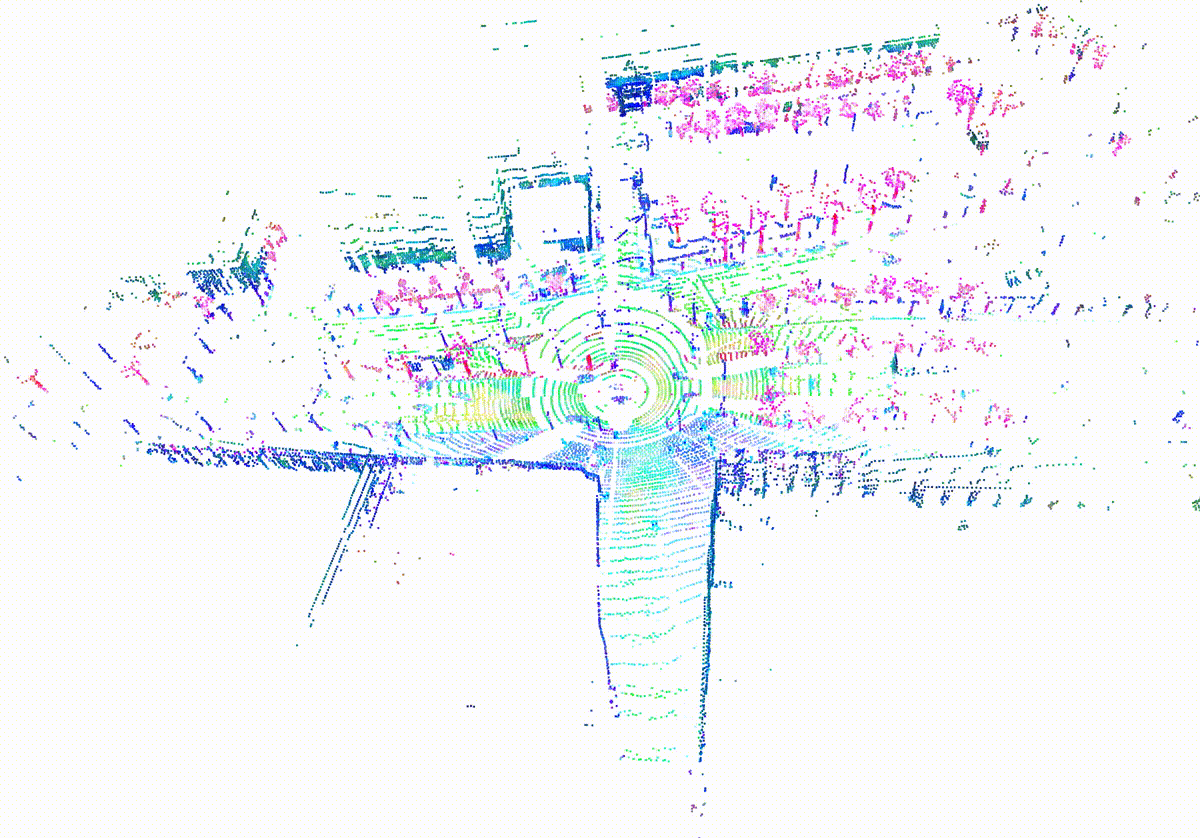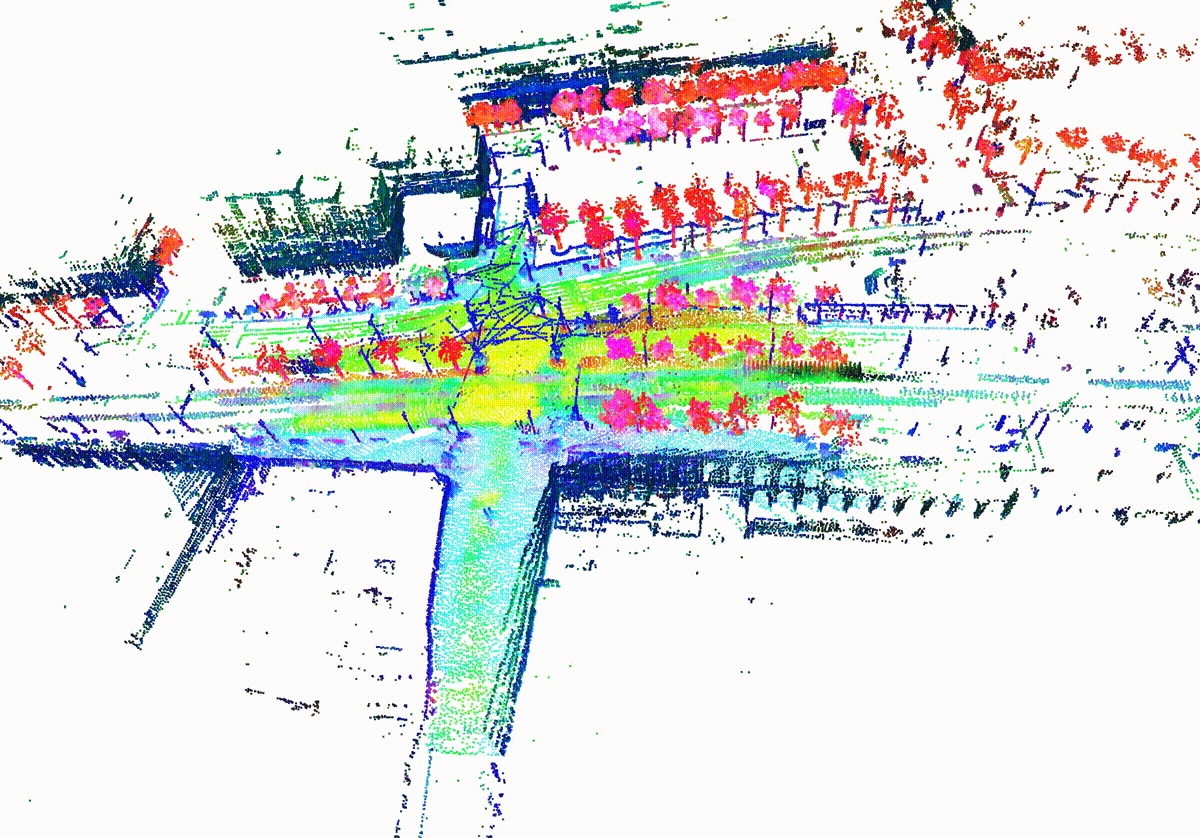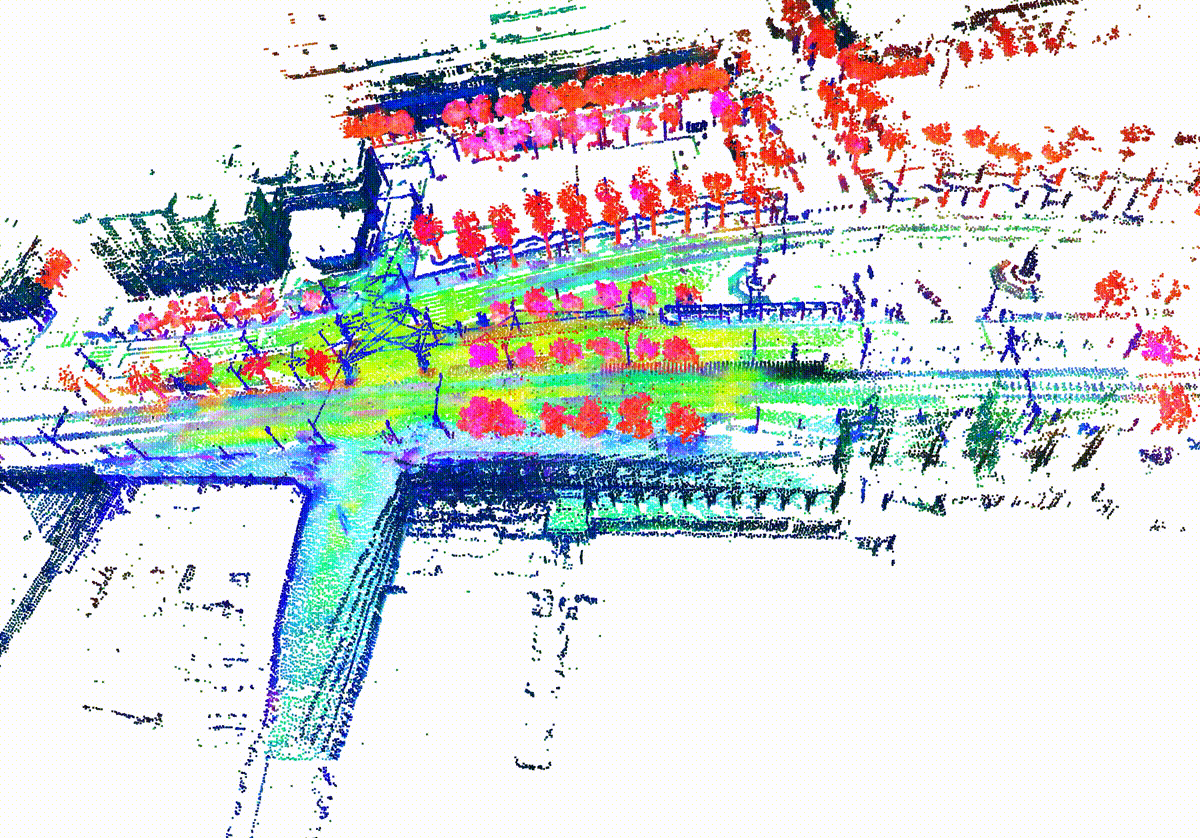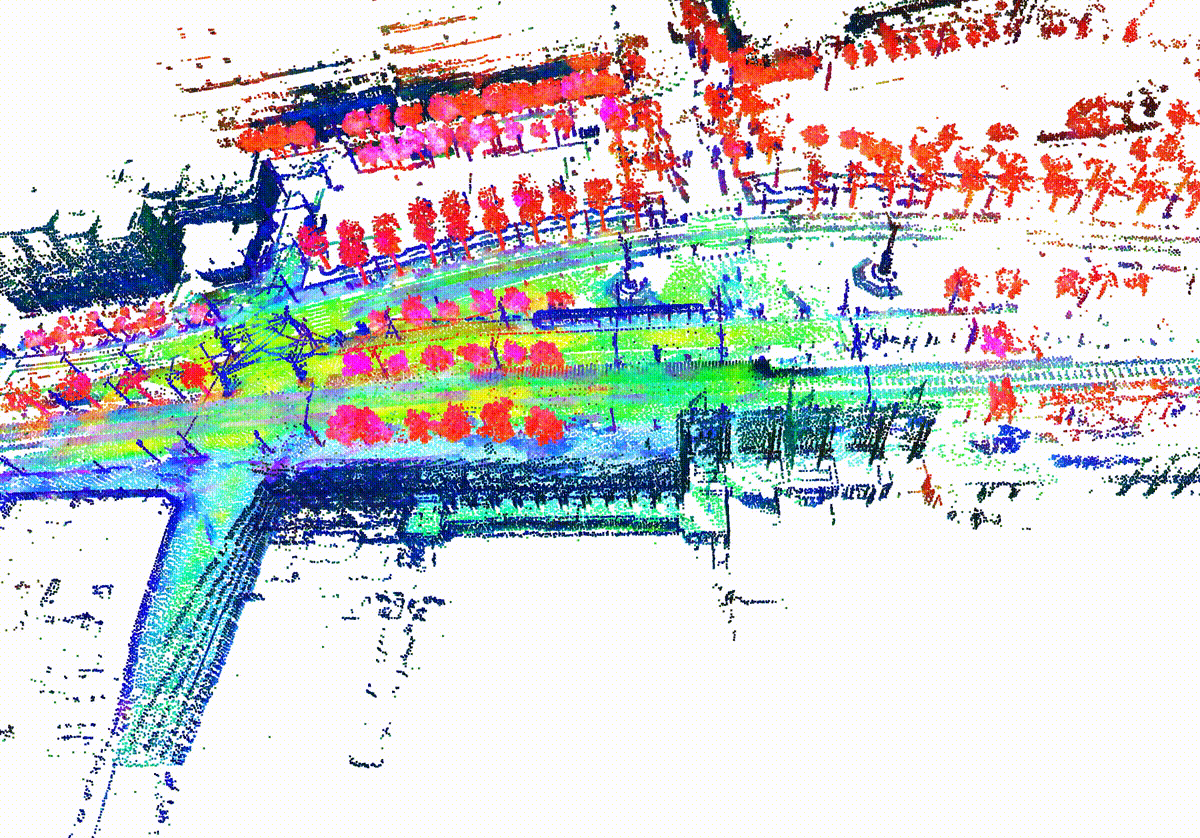
Video
Play with sound.
Motivation
LiDAR data is typically captured as a continuous stream of data, where every fraction of a second (typically 100ms) a new point cloud is available. Despite this fact, most LiDAR segmentation approaches process each frame independently due to the computational and memory complexity associated with processing large amounts of 3D point cloud data. However, perceiving with a single frame is challenging because of the point cloud sparsity, particularly at range, and has difficulty handling heavily occluded objects.
In contrast, we propose a novel online LiDAR segmentation model that recurrently updates a sparse 3D latent memory as new observations are received, efficiently and effectively accumulating geometric information as well as learned semantic embeddings from past observations. Our latent contains rich semantics that help separate different classes and provides context in currently occluded regions.
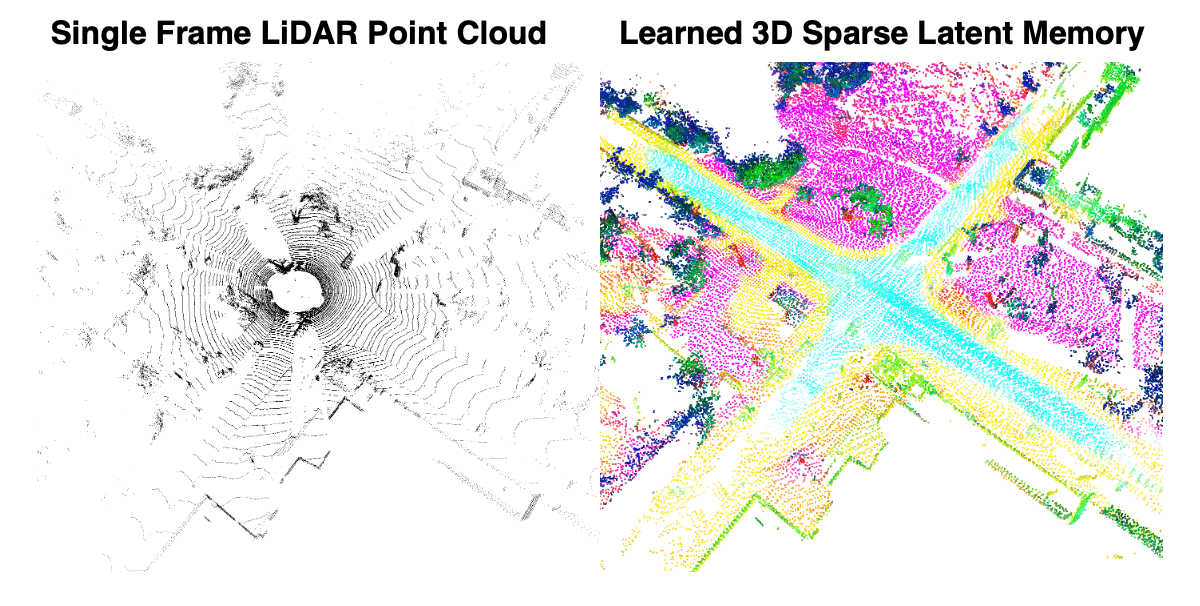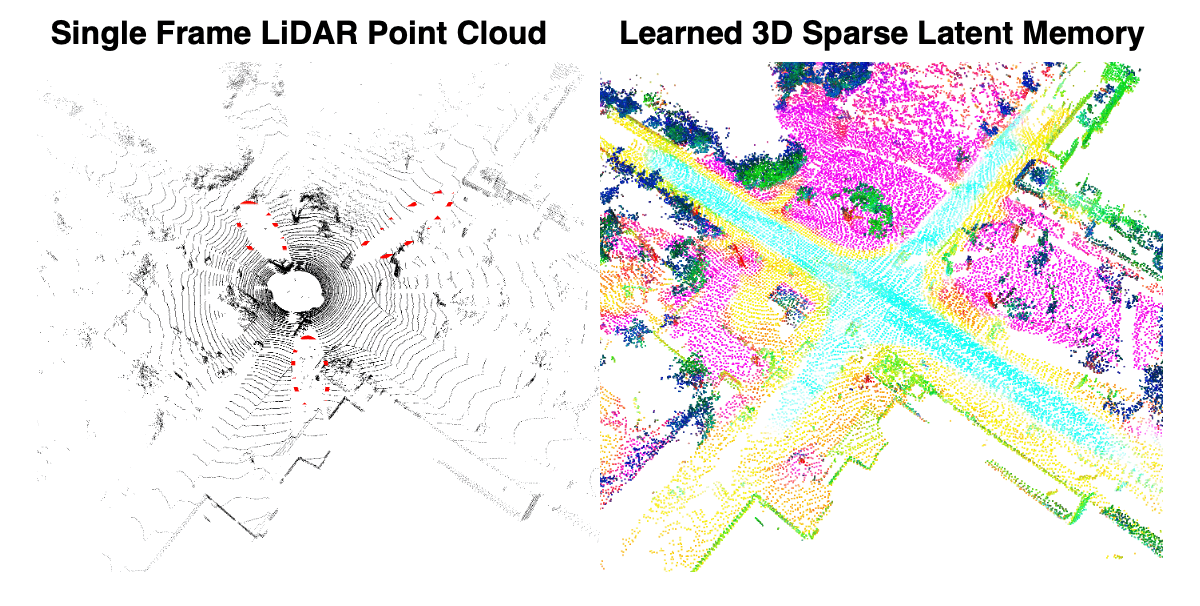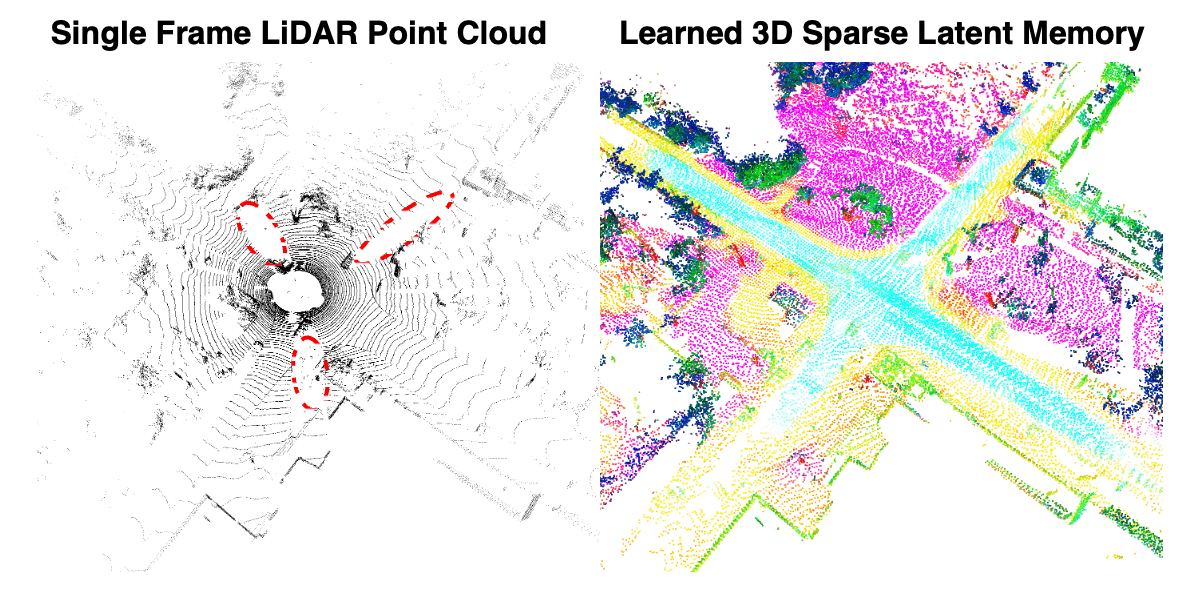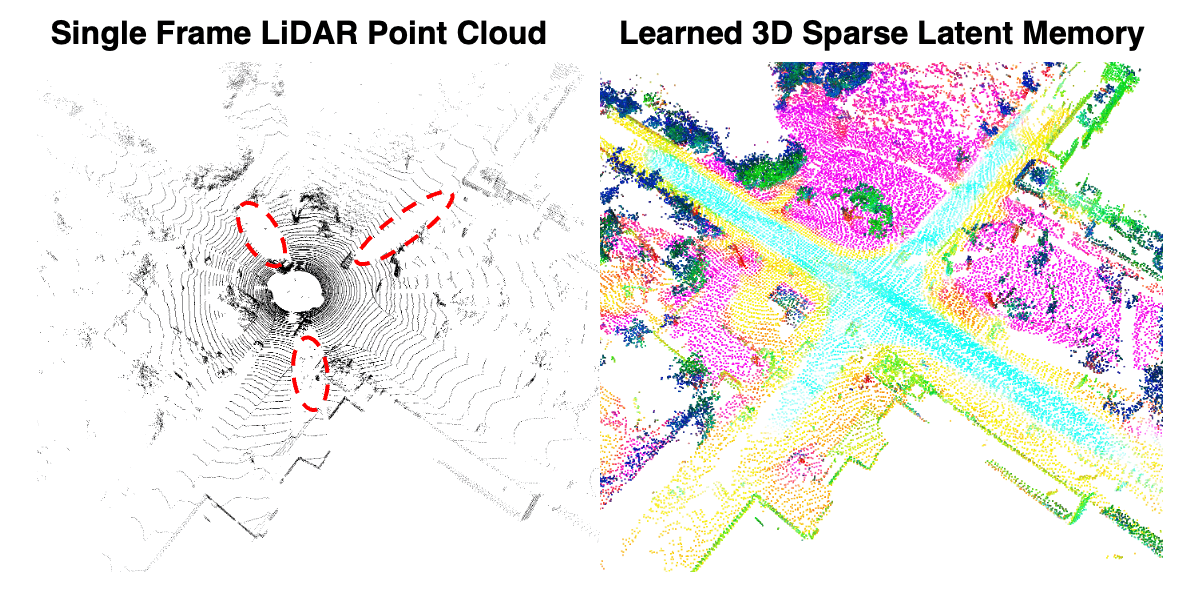
Method
We present MemorySeg, an online semantic segmentation framework for streaming LiDAR point clouds that leverages a 3D latent memory to remember the past and better handle occlusions and sparse observations.
Inference follows a three step process that is repeated every time a new LiDAR sweep is available:
- the encoder takes in the most recent LiDAR point cloud at current time t and extracts point-level and voxel-level observation embeddings,
- the latent memory is updated taking into account the voxel-level embeddings from the new observations,
- the semantic predictions are decoded by combining the point-level embeddings from the encoder and voxel-level embeddings from the updated memory.

The memory update stage faces challenges due to the changing reference frame as the SDV moves, different sparsity levels of memory and current LiDAR sweep, as well as the motion of other actors. To address these challenges, a Feature Alignment Module (FAM) is introduced to align the previous memory state with the current observation embeddings. Subsequently, an Adaptive Padding Module (APM) is utilized to fill in missing observations in the current data and add new observations to memory. Finally, a Memory Refinement Module (MRM) is employed to update the latent memory using padded observations.

Results
MemorySeg can accurately predict semantic labels in complex scenes, including those with sparse observations or partially occluded , visualized below.
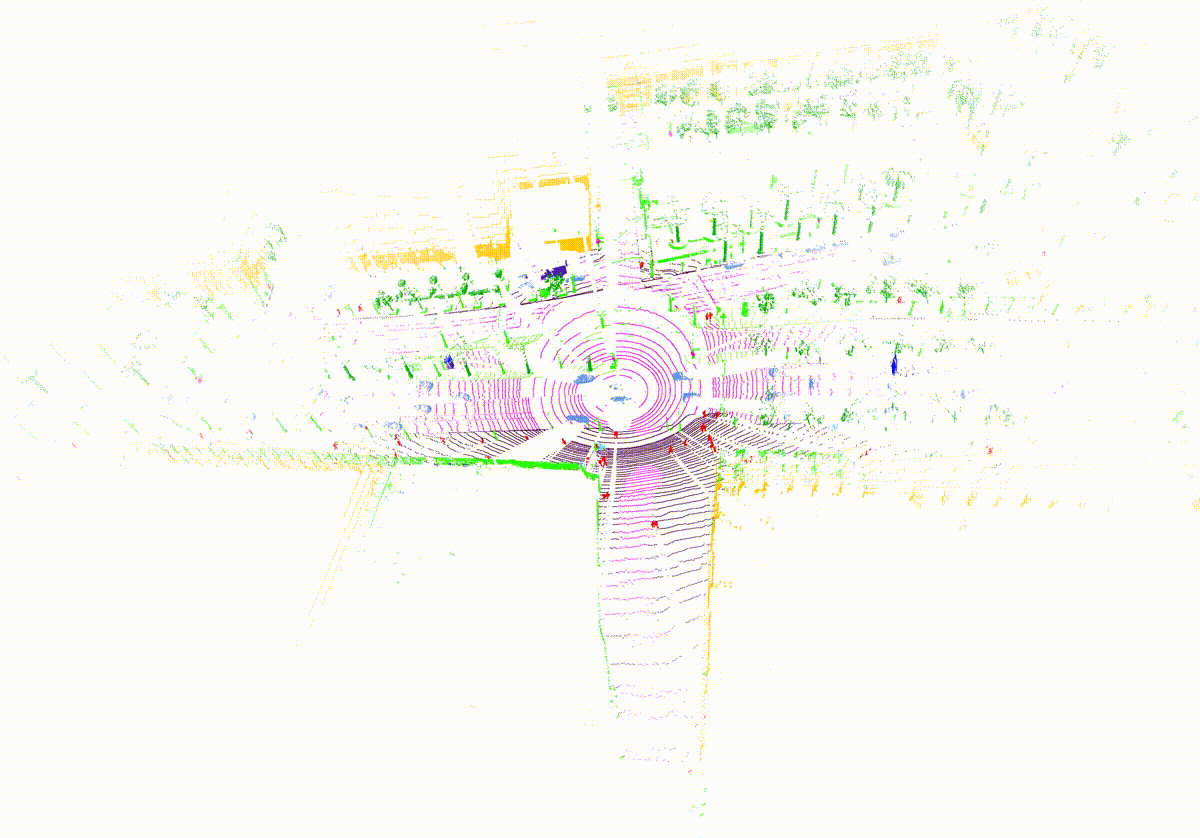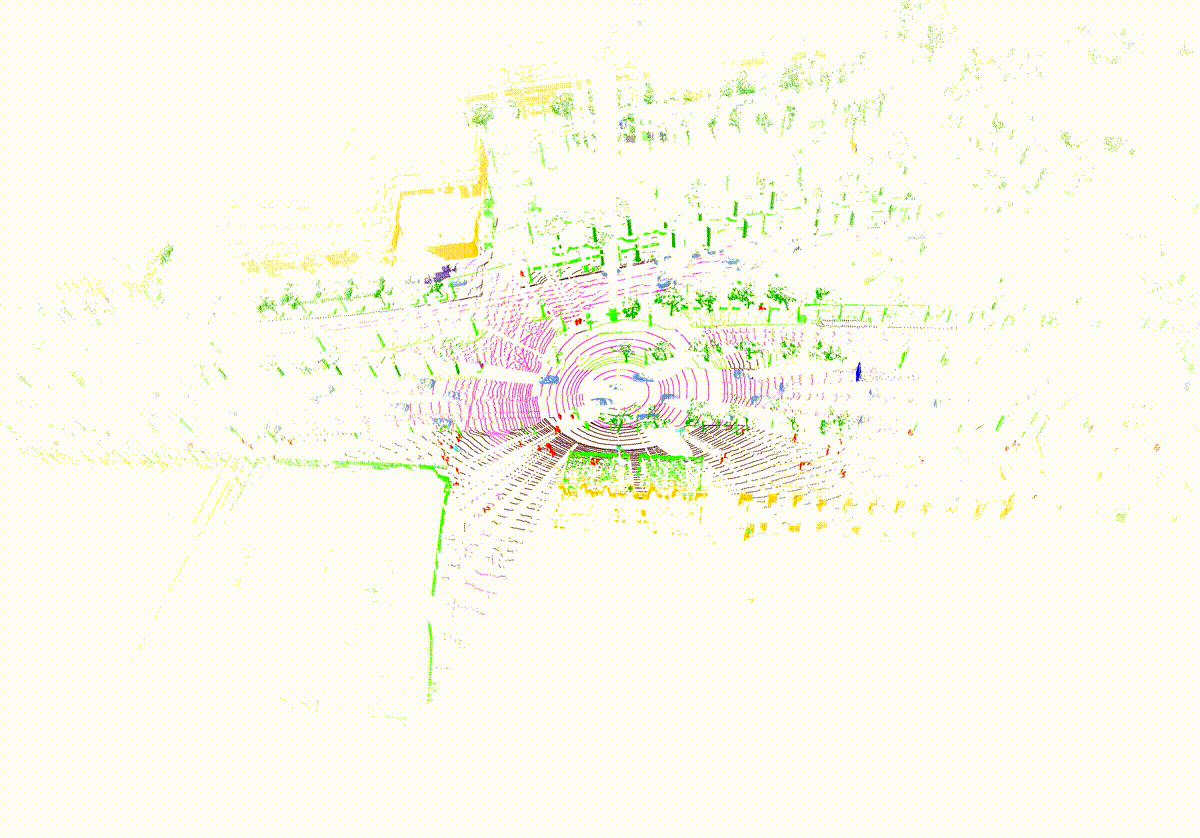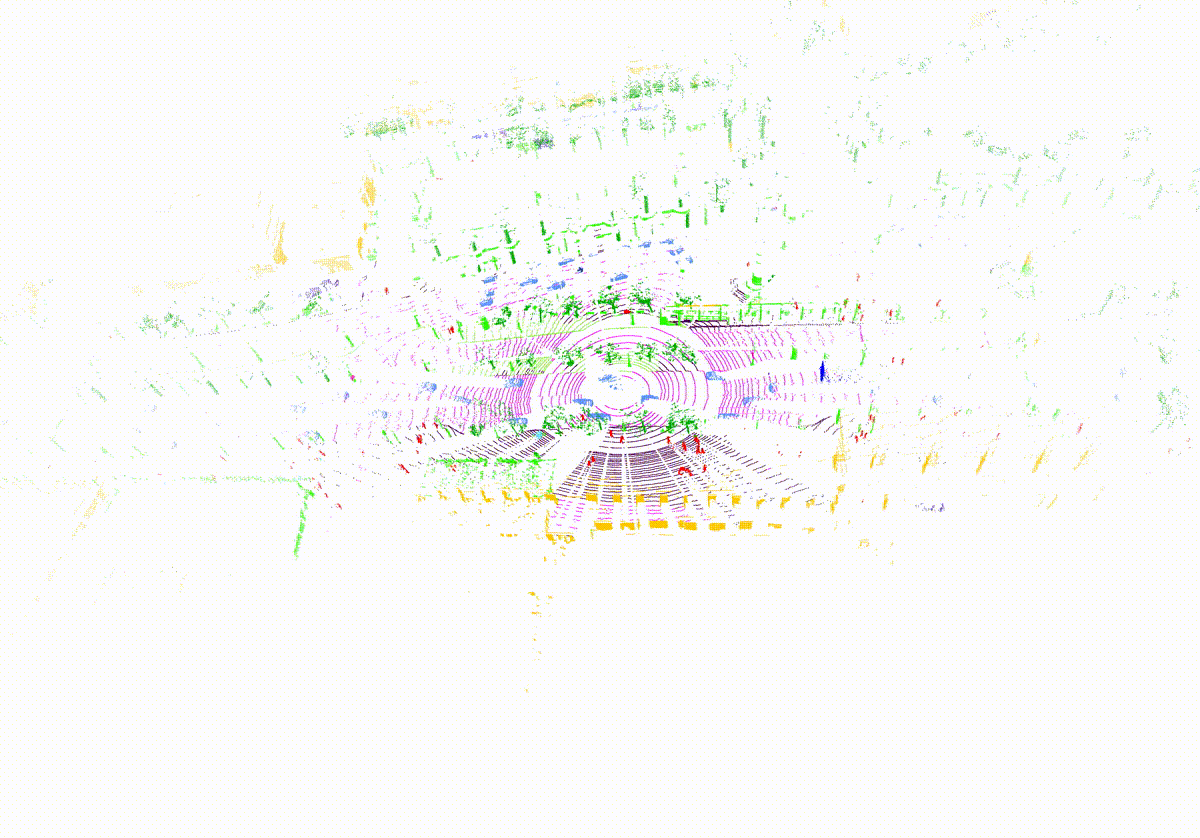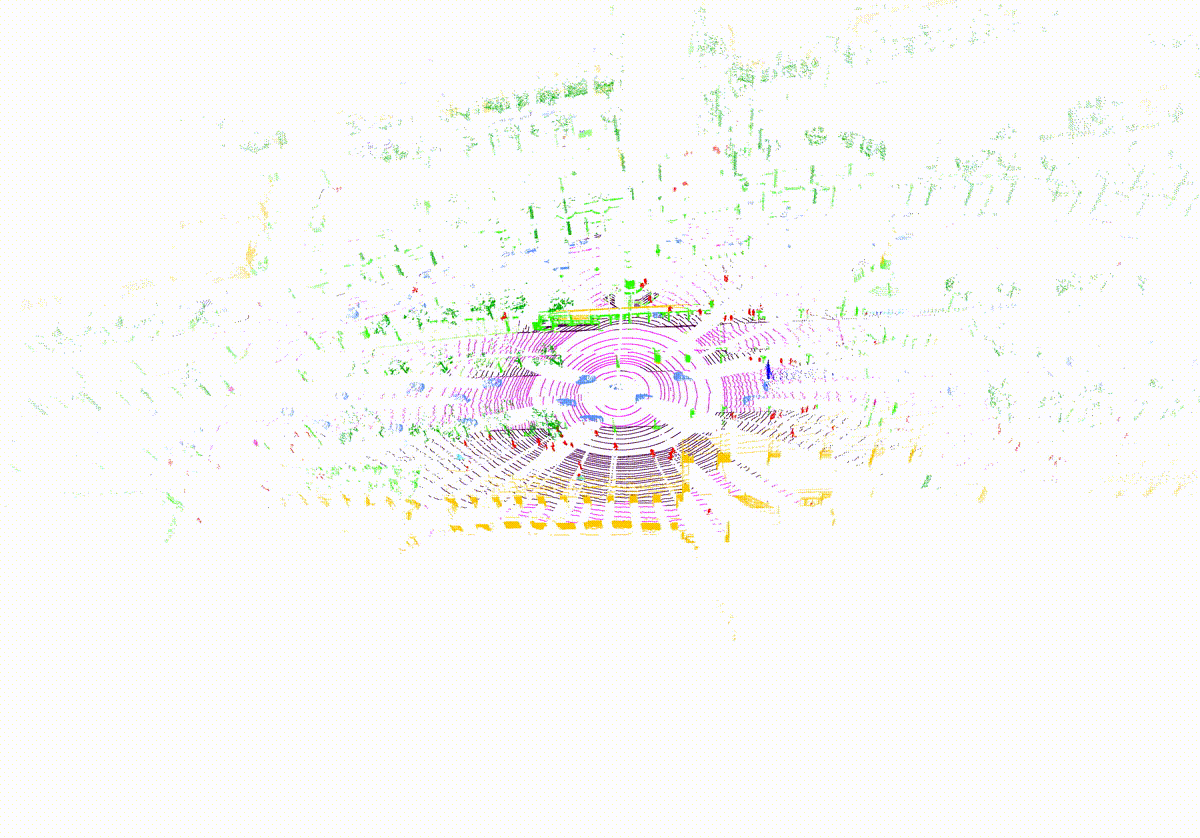
Quantitatively, MemorySeg outperforms all state of the art LiDAR-based approaches in various large-scale public benchmarks, demonstrating its generalizability across various LiDAR sensors and different geographical regions.

Test set results on SemanticKITTI multi-scan LiDAR semantic segmentation benchmark.
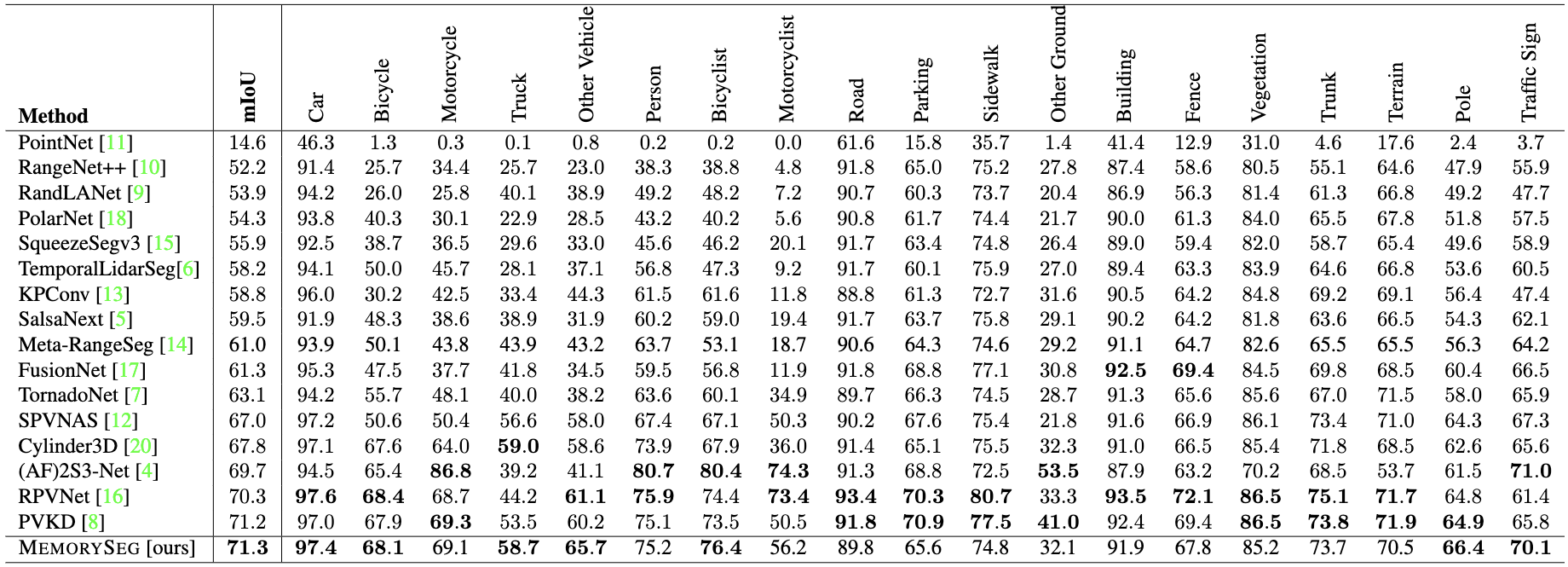
Test set results on SemanticKITTI single-scan LiDAR semantic segmentation benchmark.

Test set results on nuScenes LiDAR semantic segmentation benchmark.
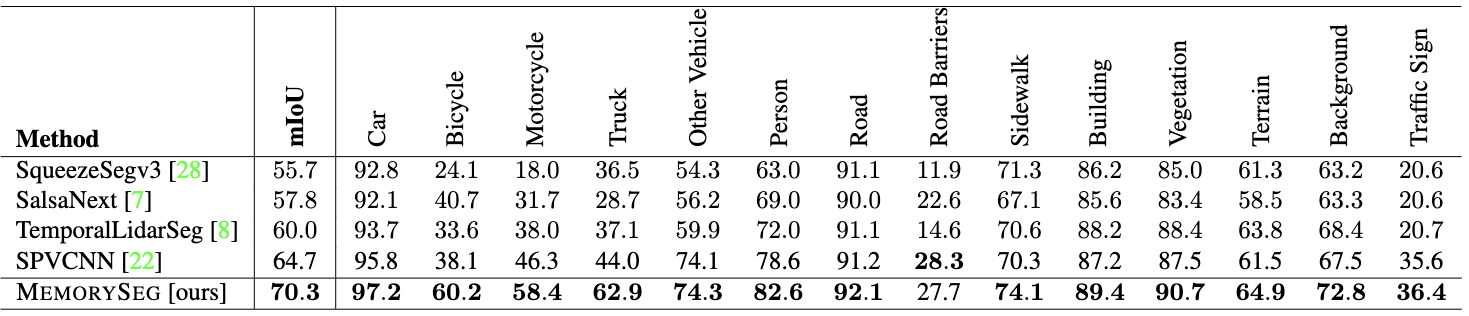
Test set results on PandaSet LiDAR semantic segmentation benchmark.
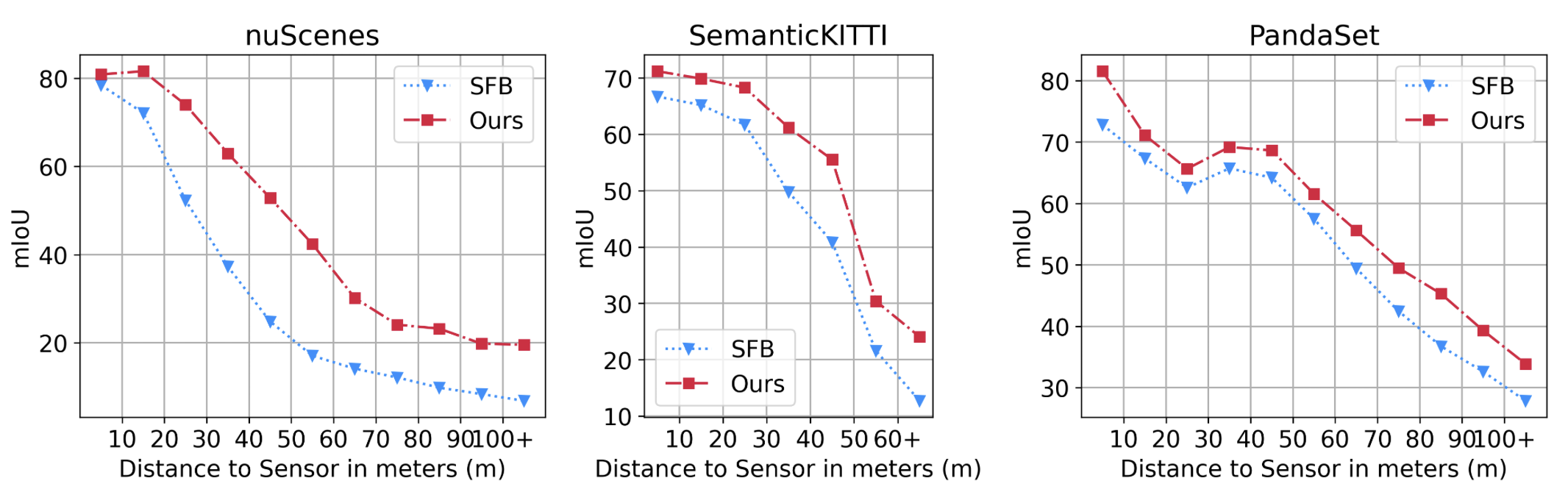
Most exisiting segmentation approaches tackle the problem of LiDAR semantic segmentation using a single frame. For a controlled experiment, we ablate our method against the single-frame baseline (SFB), by simply removing the memory from our model. MemorySeg consistently outperforms the SFB in all spatial regions in Bird’s-Eye View, with the most significant improvement observed in the long-range region of nuScenes, where points are sparser and more difficult to contextualize.
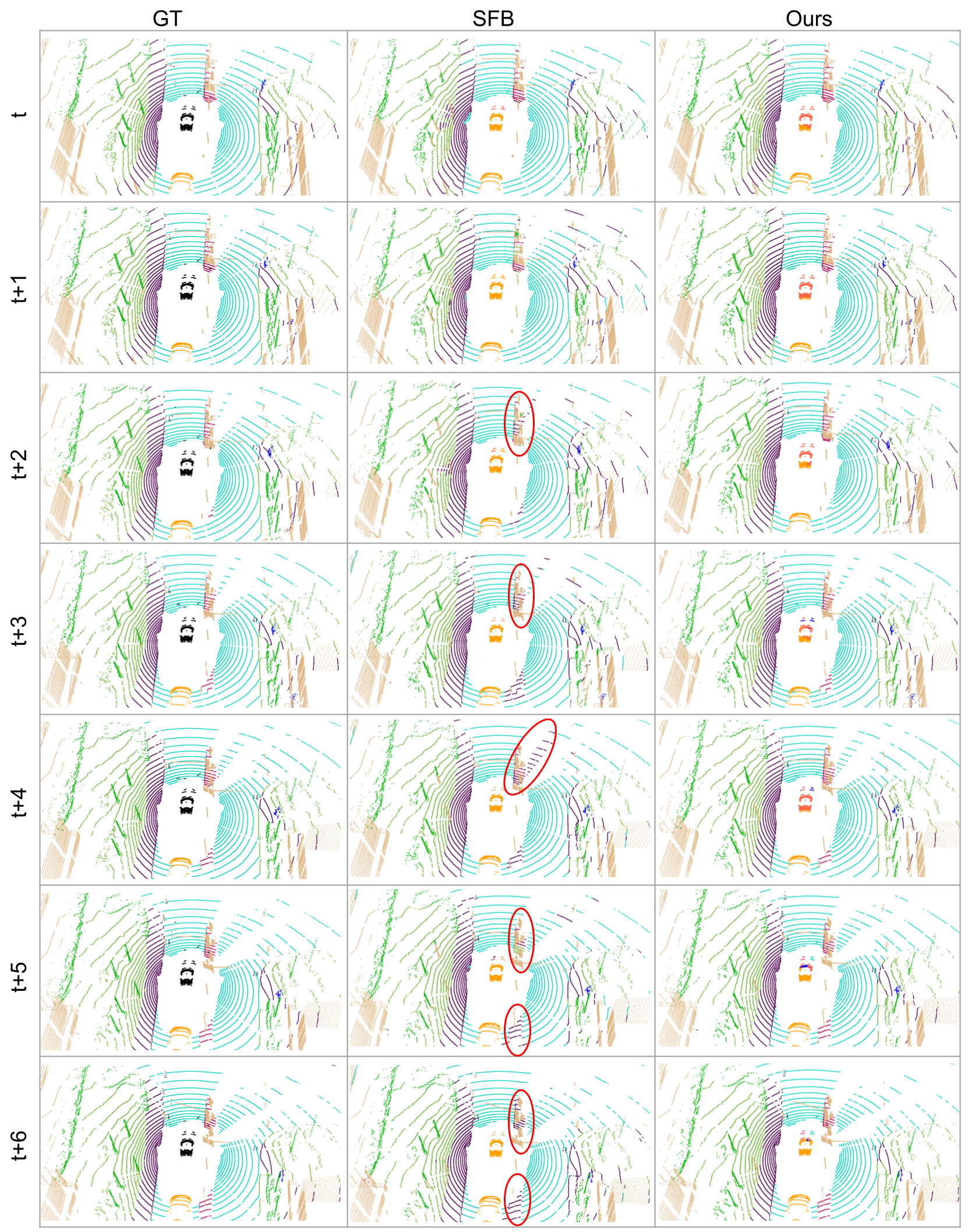
For a more detailed qualitative comparison against SFB, below we visualize the semantic predictions at each time step and highlight the failure modes. The two vehicles parked on the far left, highlighted with red circles, are difficult for semantic segmentation because of the limited observations and partial occlusions. Despite these challenges, MemorySeg consistently segments the object accurately without any flickering. Conversely, the SFB fails to identify the parked vehicle in some frames, and the segmentation results fluctuate over time.
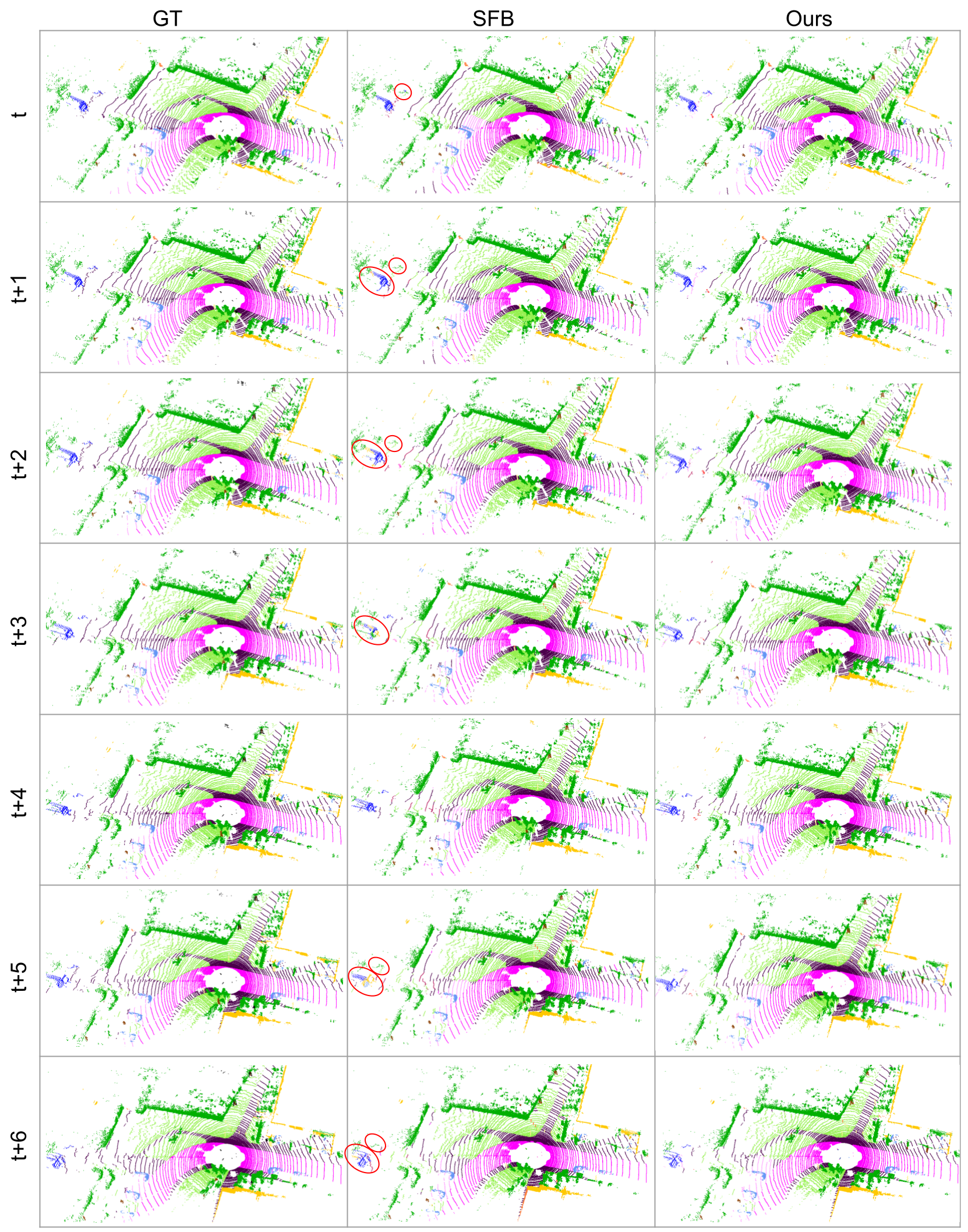
In the following scenario, we demonstrate substantial improvements in the background classes. Those classes often require an understanding of the surrounding environment to be segmented correctly. MemorySeg improves contextual reasoning by accumulating past observations using a latent memory representation. Hence, while the SFB is prone to errors, our approach yields accurate and reliable results.
BibTeX
@inproceedings{li2023memoryseg,
title = {MemorySeg: Online LiDAR Semantic Segmentation with a Latent Memory},
author = {Li, Enxu and Casas, Sergio and Urtasun, Raquel},
booktitle = {ICCV},
year = {2023},
}