Overview
We tackle the problem of realistic actor simulation. Our approach uses both nominal human driving logs and simulated long-tail scenarios in a closed-loop environment. We learn to match the expert while avoiding infractions through a combination of imitation learning and reinforcement learning.
Video
Motivation
Developing self-driving in simulation can be safer and more scalable than driving purely in the real world. In this work, we want to learn models of how humans drive in order to use them as realistic actors in simulation. In order to be realistic, models must 1) capture the nuances of human-like driving and 2) avoid infractions like collisions or driving off the road. While these may not seem contradictory at first glance, existing approaches have shortcomings resulting in less robust policies that exhibit a trade-off between the two. Our work seeks to address some of these shortcomings to improve the trade-off exhibited, and advance the Pareto frontier.
Method
Our approach involves learning with a unified closed-loop objective to match expert demonstrations under a traffic compliance constraint, while using both nominal offline data and additional simulated long-tail scenarios.
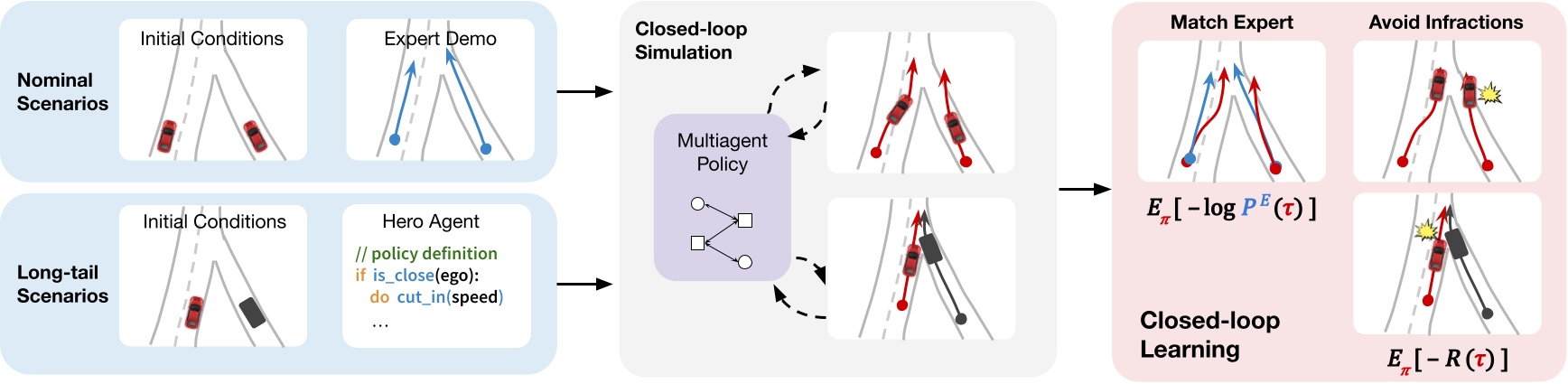
Nominal driving logs contain expert demonstrations of humans driving in the real world, but the scenarios themselves are often repetitive. For a richer learning environment, we supplement them with additional simulated long-tail scenarios that contain a hero actor that induces interesting interactions.
Nominal highway log
Long-tail actor cut-in scenario
Qualitative Comparisons
Nominal Scenarios:
We compare RTR (right) to the baseline IL (left) approach below. Note that all actors are controlled by the learned model. We draw the viewers attention to actors highlighted in pink.
IL: Collision during fork
IL: Collision during merge
RTR (ours): Collision-free overtake
RTR (ours): Safer driving during merge
Long-tail Scenarios:
We can also evaluate models on unseen long-tail scenarios. Here, blue actors are hero actors that are scripted to induce a long-tail interaction.
IL: Unreactive to merging actor
IL: Unreactive to cut-in actor
RTR (ours): Yield to merging actor
RTR (ours): Defensive swerving to avoid collision
Realism vs. Infraction avoidance
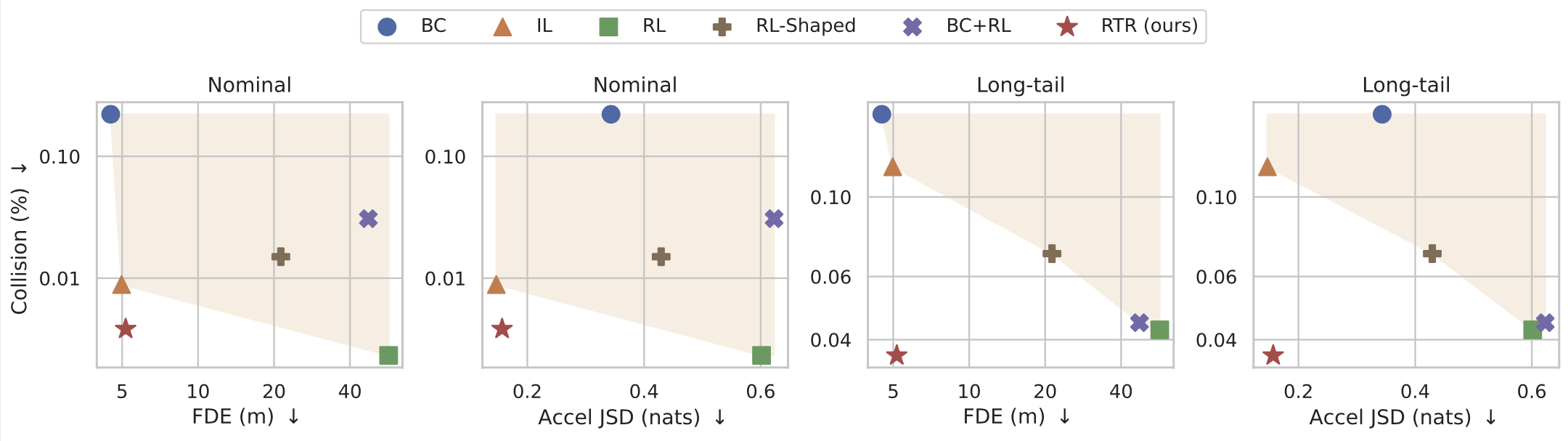
Our quantitative evaluation showed that RTR learns to avoid infractions while still capturing human-like driving. We plot collision rate compared to other measures of realism like reconstruction and distributional metrics. Several baselines varying between pure IL, pure RL, and some combination of IL+RL are shown; RTR outperforms the previous shaded Pareto frontier.
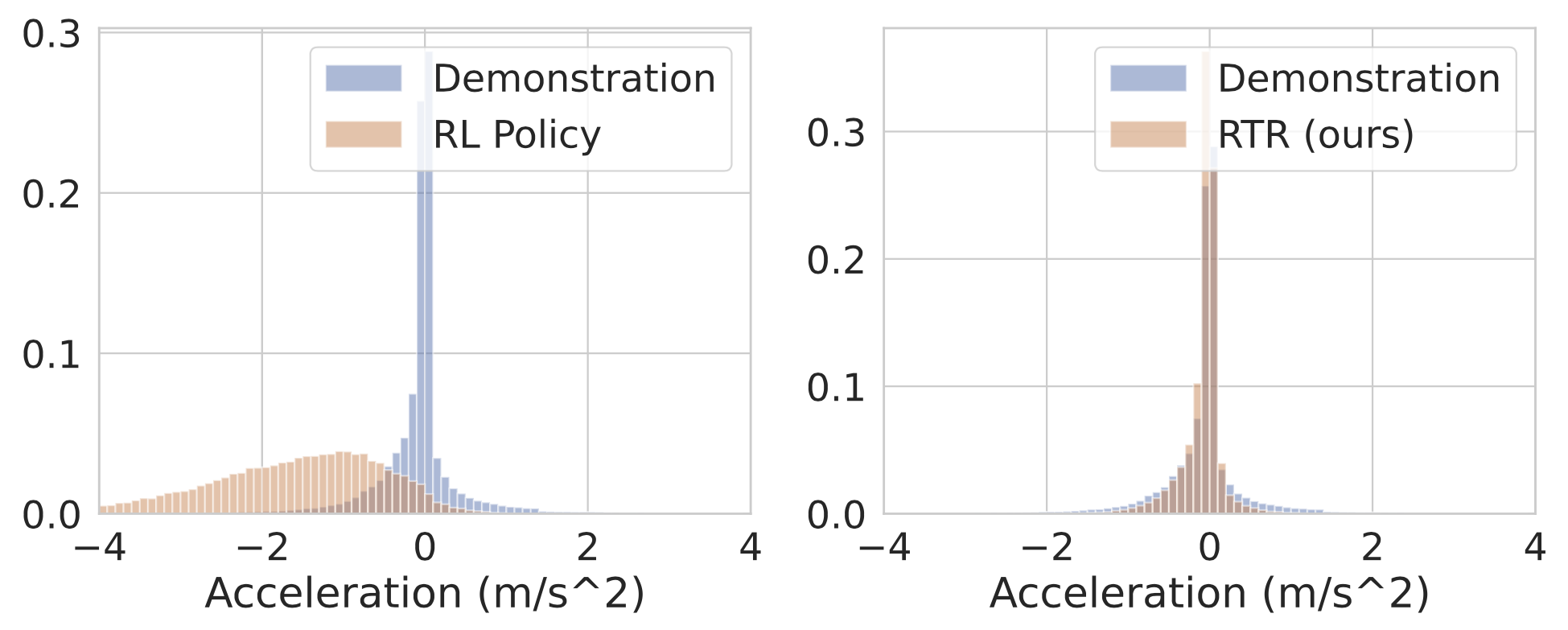
We show a histogram of acceleration values taken by the actor policies. We see that RTR learns to avoid infractions in a human-like fashion, unlike baselines such as pure RL, which learns more unrealistic behavior like slowing down too often.
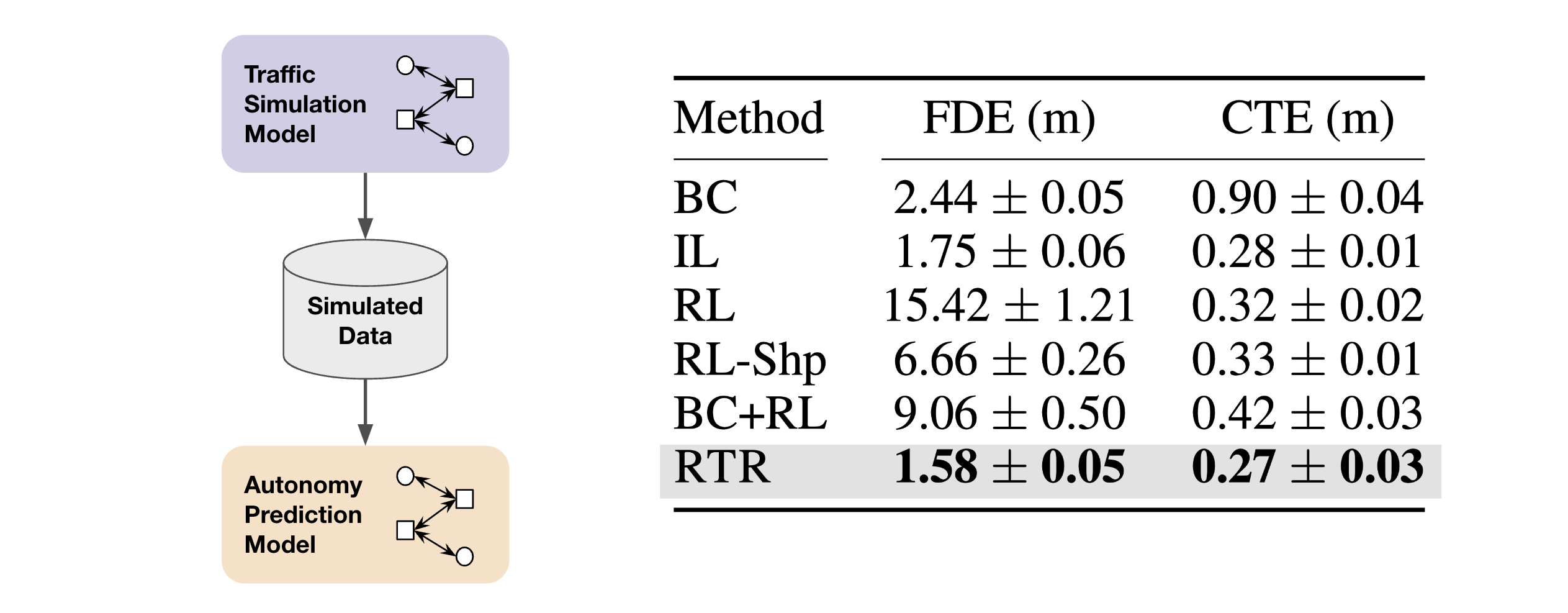
Downstream evaluation
To further evaluate actor model realism, we consider the downstream task of training prediction models on actor simulated data. We see that prediction models trained on RTR-simulated data achieve the best metrics on held out real data, suggesting that RTR simulations are more realistic and have a lower domain gap compared to baselines.
Conclusion
We have presented RTR, a method for learning realistic traffic agents with closed-loop IL+RL using both real-world logs and procedurally generated long-tail scenarios. When compared to a range of competitive baselines, RTR obtains significantly better tradeoffs between realism and infraction-avoidance. Additionally, considerably improved downstream prediction metrics are obtained when using RTR-simulated data for training, suggesting that RTR simulations are more realistic. We believe this serves as a crucial step towards more effective applications of traffic simulation for self-driving.
BibTeX
@inproceedings{zhang2023learning,
title = {Learning Realistic Traffic Agents in Closed-loop},
author = {Chris Zhang and James Tu and Lunjun Zhang and Kelvin Wong and Simon Suo and Raquel Urtasun},
booktitle = {7th Annual Conference on Robot Learning},
year = {2023},
url = {https://openreview.net/forum?id=yobahDU4HPP}
} 